AI for AI safety
(This is the fourth essay in a series that I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.)
1. Introduction and summary
In my last essay, I offered a high-level framework for thinking about the path from here to safe superintelligence. This framework emphasized the role of three key “security factors” – namely:
- Safety progress: our ability to develop new levels of AI capability safely,
- Risk evaluation: our ability to track and forecast the level of risk that a given sort of AI capability development involves, and
- Capability restraint: our ability to steer and restrain AI capability development when doing so is necessary for maintaining safety.
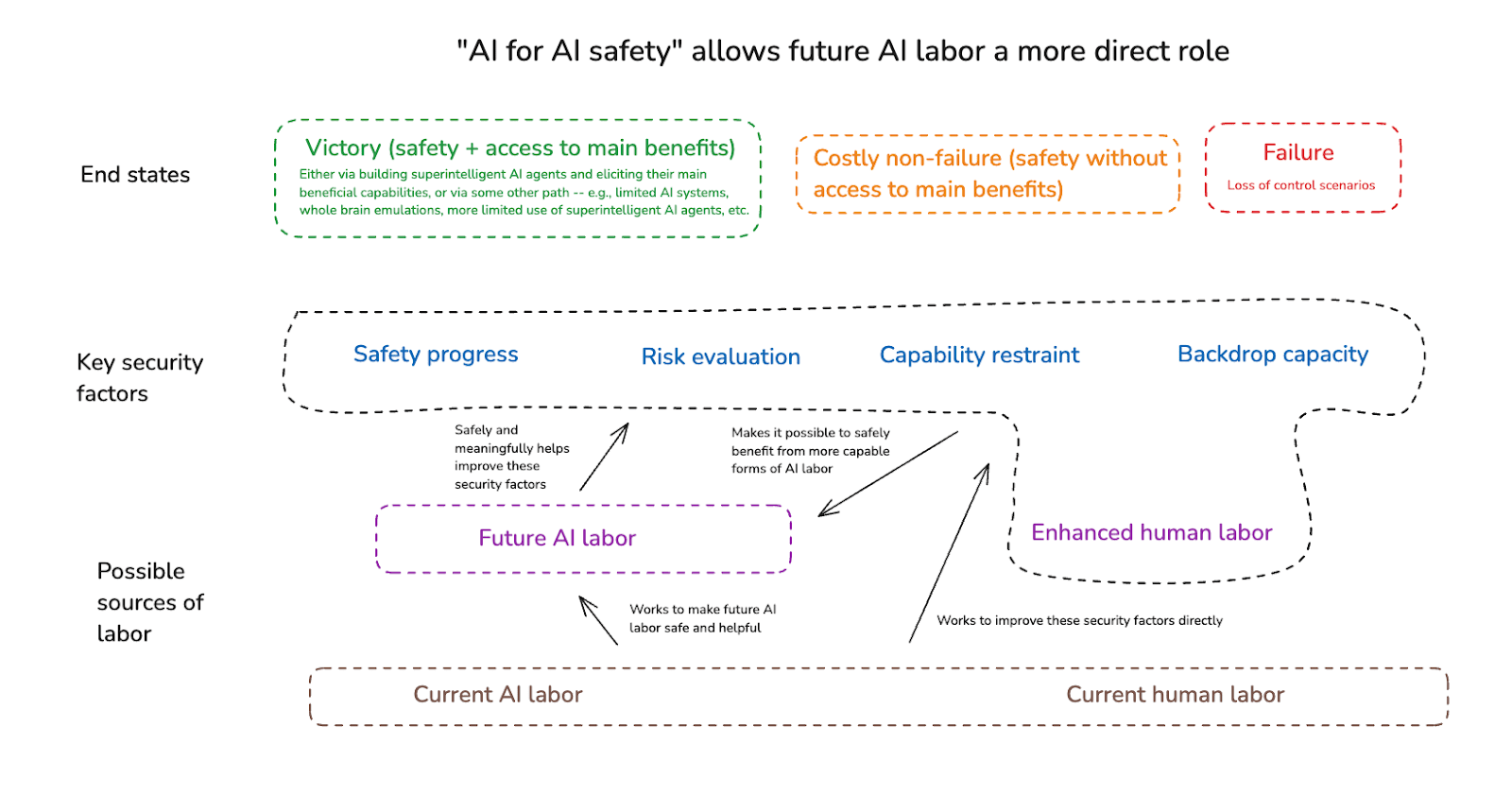
In this essay, I argue for the crucial importance of what I call “AI for AI safety” – that is, the differential use of frontier AI labor to strengthen these security factors. I frame this in terms of the interplay between two feedback loops, namely:
- The AI capabilities feedback loop: access to increasingly capable AI systems driving further progress in AI capabilities.
- The AI safety feedback loop: safe access to increasingly capable AI systems driving improvements to the security factors above.
AI for AI safety is about continually using the latter feedback loop to either outpace or restrain the former.

The basic argument for the importance of AI for AI safety is obvious: AI has the potential to unlock massive productivity gains, so of course we want to use this productivity for safety-relevant applications wherever possible. But it becomes particularly clear, I think, in light of the way that progress on AI capabilities is likely, by default, to be massively accelerated by large amounts of fast, high-quality AI labor. If our ability to make increasingly capable AI systems safe can’t benefit from such labor in a comparable way, then at least for relatively hard problem profiles, and absent large amounts of capability restraint, I think we’re likely headed for disaster.
I also discuss the timing of our efforts at AI for AI safety. In particular, I highlight what I call the “AI for AI safety sweet spot” – that is, a zone of capability development where frontier AI systems are capable enough to radically improve the security factors above, but not yet capable enough (given our countermeasures) to disempower humanity. I don’t think it’s clear that we’ll be able to benefit from such a sweet spot – and especially not, for long. But I think it’s a useful concept to have in mind, and an important possible focal point for our efforts at capability restraint.

The big question, though, is whether we’ll actually be able to do AI for AI safety at the scale and potency necessary to make a meaningful difference. I close the essay by introducing the concerns in this respect that I view as most serious – both more fundamental concerns (centered on elicitation/evaluation failures, differential sabotage, and dangerous rogue options), and more practical concerns (centered on e.g. the available amounts of time and political will). I then examine these concerns in more detail in the next essay, in the context of the application of “AI for AI safety” that I view as most important – namely, automated alignment research.
2. What is AI for AI safety?
By “AI for AI safety,” I mean: any strategy that makes central use of future AI labor to improve our civilization’s competence with respect to the alignment problem, without assuming a need for radical, human-labor-driven alignment progress first. Let’s go through a few options in this respect, for the different security factors above.
- Safety progress:
- Probably the most prominent application of AI for AI safety is automated alignment research – that is, using AIs to help with research on shaping AI motivations and local options in desirable ways.1
- AIs already play an important role in various processes closely relevant to alignment – e.g. evaluating AI outputs during training, labeling neurons in the context of mechanistic interpretability, monitoring AI chains of thought for reward-hacking behaviors, identifying which transcripts in an experiment contain alignment-faking behaviors, classifying problematic inputs and outputs for the purpose of preventing jailbreaks, etc. And of course, alignment researchers can benefit from the same general AI tools (e.g. coding, writing, brainstorming) that everyone else can; and the same tools for ML engineering, in particular, that other ML researchers can.
- In the future, though, we can imagine AIs that more fully automate the complete pipeline involved in generating new alignment-relevant ideas, critiquing them, identifying and running informative experiments, interpreting the results, and so on.2 Indeed, automation of this kind is a key focal point for safety efforts at some existing AI labs3; and in my view, it’s the most important application of AI for AI safety. In my next essay, I’ll examine it in depth.
- Beyond automated alignment research, though, advanced AIs can also help with hardening the broader world so that it is more robust to efforts by rogue AIs to seek power.4 For example:
- Cybersecurity: AIs could assist with improving the world’s cybersecurity, thereby making it much more difficult for rogue AIs to self-exfiltrate, to hack into unauthorized compute resources, etc. Indeed, if the offense-defense balance in cybersecurity is sufficiently favorable (and in particular: if enough code can be formally verified as secure using AI labor), then in principle AI labor could radically change the degree of baseline cybersecurity in the world at large.5
- Monitoring for rogue activity: AIs could assist in monitoring for rogue AI activity, thereby making it harder for rogue AIs to operate undetected.6
- Anti-manipulation: We could develop novel AI tools for detecting and blocking AI persuasion techniques aimed at manipulating humans.7
- Countermeasures to specific threat models: AIs could assist in developing countermeasures to specific threat models for rogue AI attack, like biological weapons (via e.g. developing cheap and rapid diagnostics; improving disease surveillance, PPE and vaccine pipelines; developing novel countermeasures like far-UVC; etc).
- Eating free energy: More generally, non-rogue AIs operating and competing in the economy at large makes it harder for rogue AIs to easily gain outsized amounts of money and influence. (Though: I doubt this is the most leveraged place for safety efforts to focus).8
- Probably the most prominent application of AI for AI safety is automated alignment research – that is, using AIs to help with research on shaping AI motivations and local options in desirable ways.1
- Risk evaluation:
- Possibilities for automated risk evaluation include: automating the pipeline involved in designing and running evals, using AIs to help create and assess safety cases and cost-benefit analyses, using AI labor to assist in creating model organisms and other sources of evidence about AI risks, and using AI labor to generally improve our scientific understanding of how AI works. (Much of this intersects closely with automated alignment research, since progress on making AIs safe is closely tied to understanding how safe they are).
- The potential role for AI labor in forecasting is perhaps especially notable, in that forecasting affords especially concrete and quantitative feedback loops for use both in training the AIs, and in assessing the quality of their task-performance.
- And to the extent the general quality of our collective epistemology feeds into our risk evaluation in particular, AI can help notably with that too.9
- Capability restraint:
- Individual caution: AI-assisted risk evaluation and forecasting can promote individual caution by helping relevant actors understand better what will happen if they engage in a given form of AI development/deployment; and AI advice might be able to help actors make wiser decisions, by their own lights, more generally.
- Coordination: AIs might be able to help significantly with facilitating different forms of coordination – for example, by functioning as negotiators, identifying more viable and mutually-beneficial deals, designing mechanisms for making relevant commitments more credible and verifiable, etc.
- Restricted options and enforcement: AIs might be able to help develop new and/or better technologies (including: AI technologies) for monitoring and enforcement – e.g., on-chip monitoring mechanisms, offensive cyber techniques for shutting down dangerous projects, highly trustworthy and privacy-preserving inspection capacity, etc. They could also help with designing and implementing more effective policies on issues like export controls and domestic regulation. And in the limit of direct military enforcement, obviously AIs could play a role in the relevant militaries.10
- Broader attitudes and incentives: AI labor can also play a role in shaping the broader attitudes and incentives that determine how our civilization responds to misalignment risk – e.g., by helping with communication about the risks at stake.
In my previous essay, I also included a catch-all security factor that I called “backdrop capacity,” which covered our civilization’s general levels of abundance, happiness, health, efficiency, institution quality, epistemology, wisdom, virtue, and so on.
- Relative to the more specific security factors above, the influence of backdrop capacity on loss of control risk is more diffuse, so I doubt that safety-focused efforts should actively focus on it.
- But I do think that at least in scenarios where there’s time for AI to significantly impact the economy before full-blown superintelligence is created, AI labor will likely be able to improve our backdrop capacity in a huge number of ways,11 and that this could make an important difference to our civilizational competence.12
I’ll also note one final application of AI for AI safety: namely, using AI labor to assist in unlocking the sort of enhanced human labor I discussed in my last essay, which could then itself be used to improve the security factors discussed above.
- Thus, AI labor could be used for developing the science and technology necessary for whole brain emulation – e.g., for connectomics, brain-scanning, relevant neuroscience, animal experiments, etc – and for other routes to enhanced human labor as well – e.g., brain computer interfaces (BCI) and other biological interventions.
Analyzing all of these potential applications of AI for AI safety in detail is beyond my purpose here. I hope, though, that the broad vibe is clear. AI labor can play a role similar to human labor in many domains. And in the limit (including: the limit of trust), it can function as a full and superior substitute across the board. So anything you might’ve wanted to do with humans is in principle a candidate for “AI for AI safety” – and this includes improvements to all the security factors above.
2.1 A tale of two feedback loops
Here’s a way of thinking about “AI for AI safety” that I’ve found useful.
The scariest AI scenarios, in my opinion, involve what we might call an “AI capability feedback loop,” in which the automation of the R&D involved in advancing AI capabilities leads to rapid escalation of frontier AI capabilities – the so-called “intelligence explosion.”13 Here’s a simple diagram, applied to the toy model of AI safety I described in my last essay (and focusing, for even more simplicity, only on a single actor).14
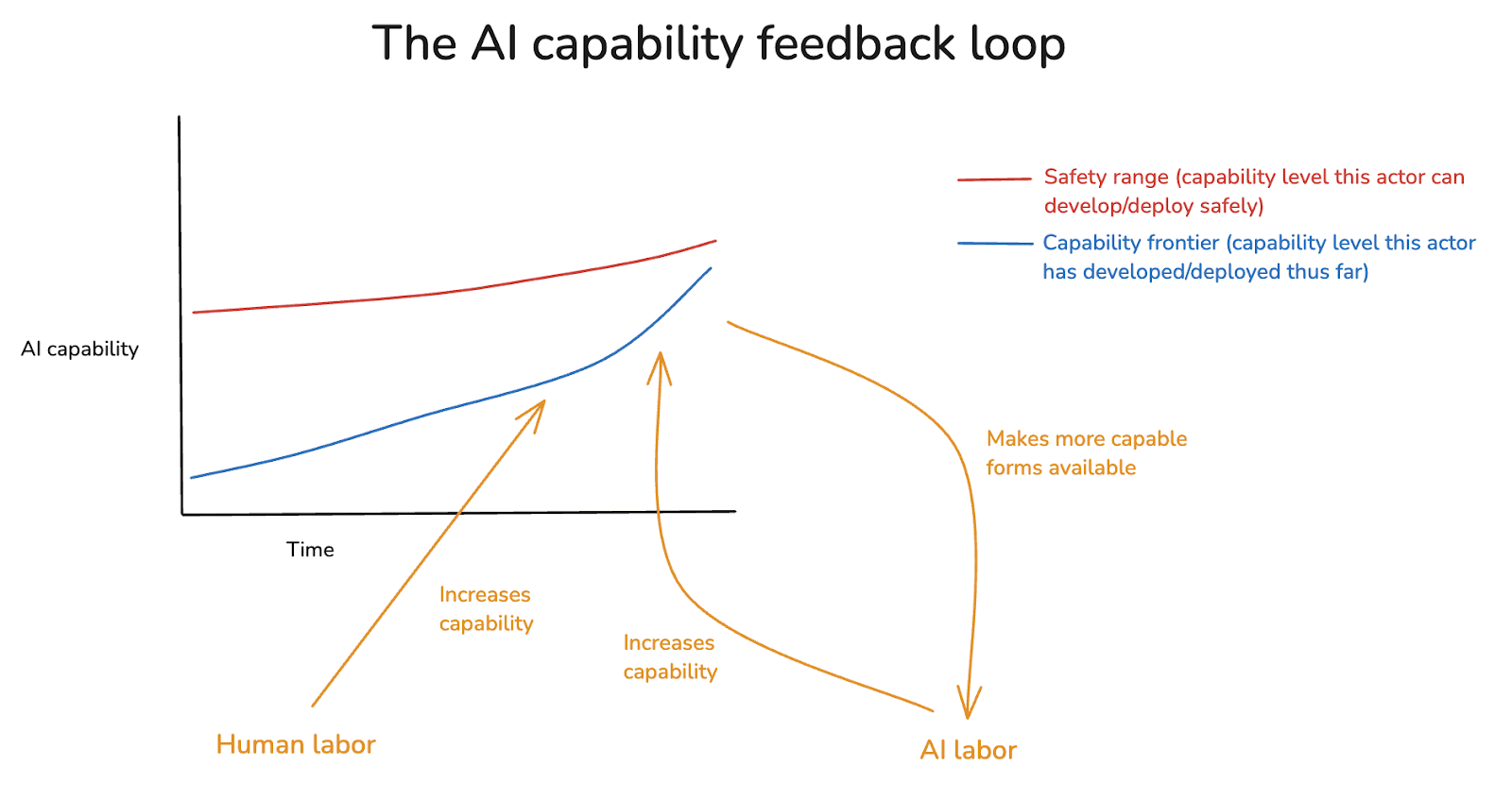
In the diagram, there are two sources of labor being devoted to making frontier AI systems more capable – normal human labor, and AI labor. And as the capability frontier advances, so does the quality of the AI labor being used to advance it.
It’s an open question exactly where this feedback loop leads, and on what timescales. In the bad case, though, this feedback loop quickly drives the capability frontier outside of the safety range, leading to loss of control.
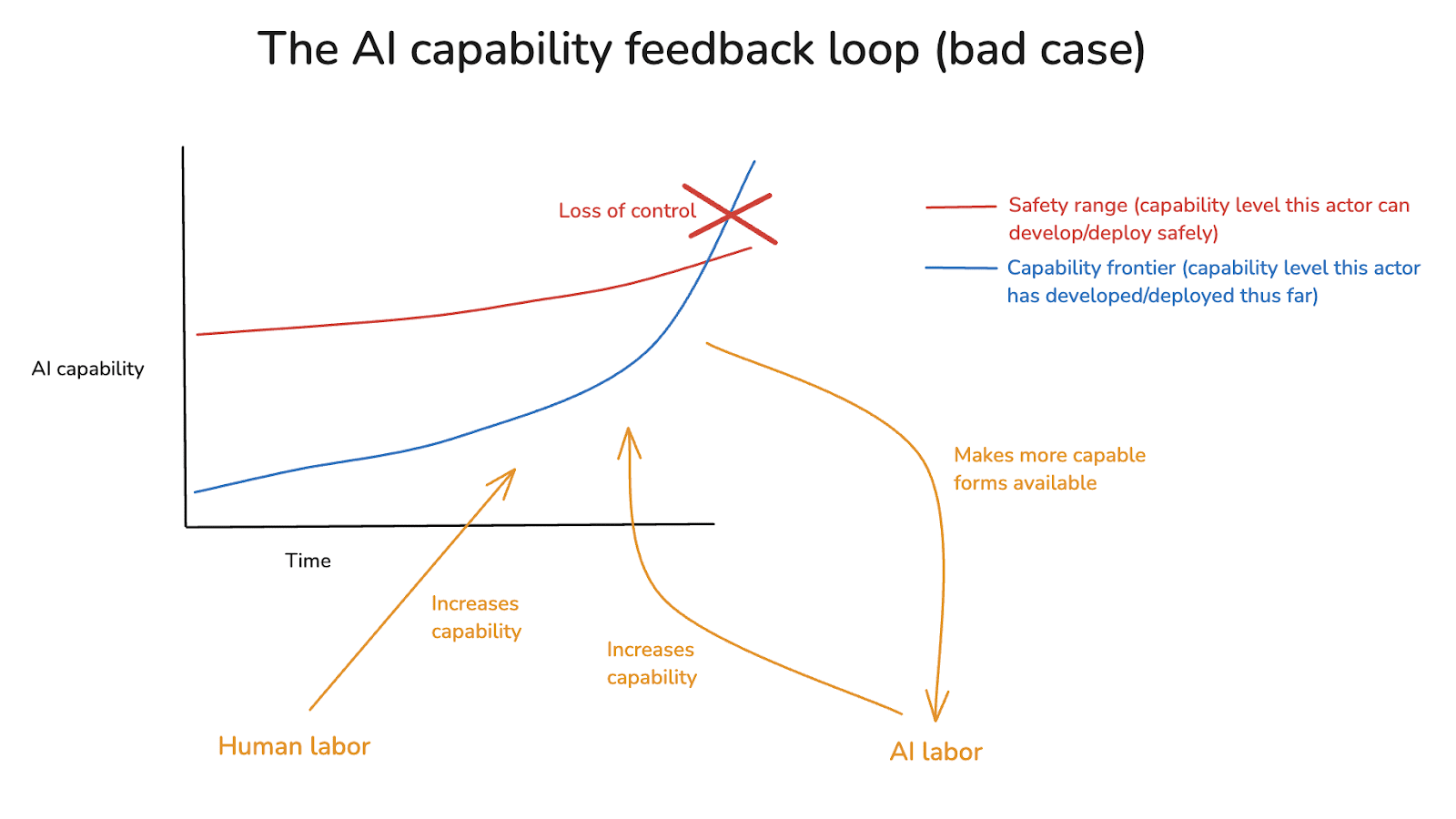
By contrast, many forms of “AI for AI safety” focus on strengthening a different feedback loop, which I’ll call the “AI safety feedback loop.” Here, safe forms of frontier AI labor get directed towards improving the security factors I discussed above, which in turn make it possible to get safe access to the benefits of more capable forms of AI labor. Thus, in a diagram:

So one way of thinking about “AI for AI safety” is in terms of the interplay between these two feedback loops – where the aim is for the AI safety feedback loop to continually secure the AI capability feedback loop, via some combination of (a) outpacing it (i.e., by expanding the safety range fast enough that the capability frontier never exceeds it),15 and (b) restraining it (i.e., strengthening our capacities for risk evaluation and capability restraint enough to hold off on pushing the capability frontier when necessary).16
2.2 Contrast with “need human-labor-driven radical alignment progress” views
“AI for AI safety” is not an especially specific strategy. Indeed, in some sense, its central claim is just: “AI labor is really important for dealing well with the alignment problem; try really hard to use AI labor to help.” And this might sound obvious.
Still, some people disagree. In particular: some people endorse what I’ll call “need human-labor-driven radical alignment progress views,” on which AI labor will remain some combination of unhelpful and unsafe absent radical progress on alignment – progress that therefore needs to be driven by some form of human labor instead.17 Thus, in a diagram:
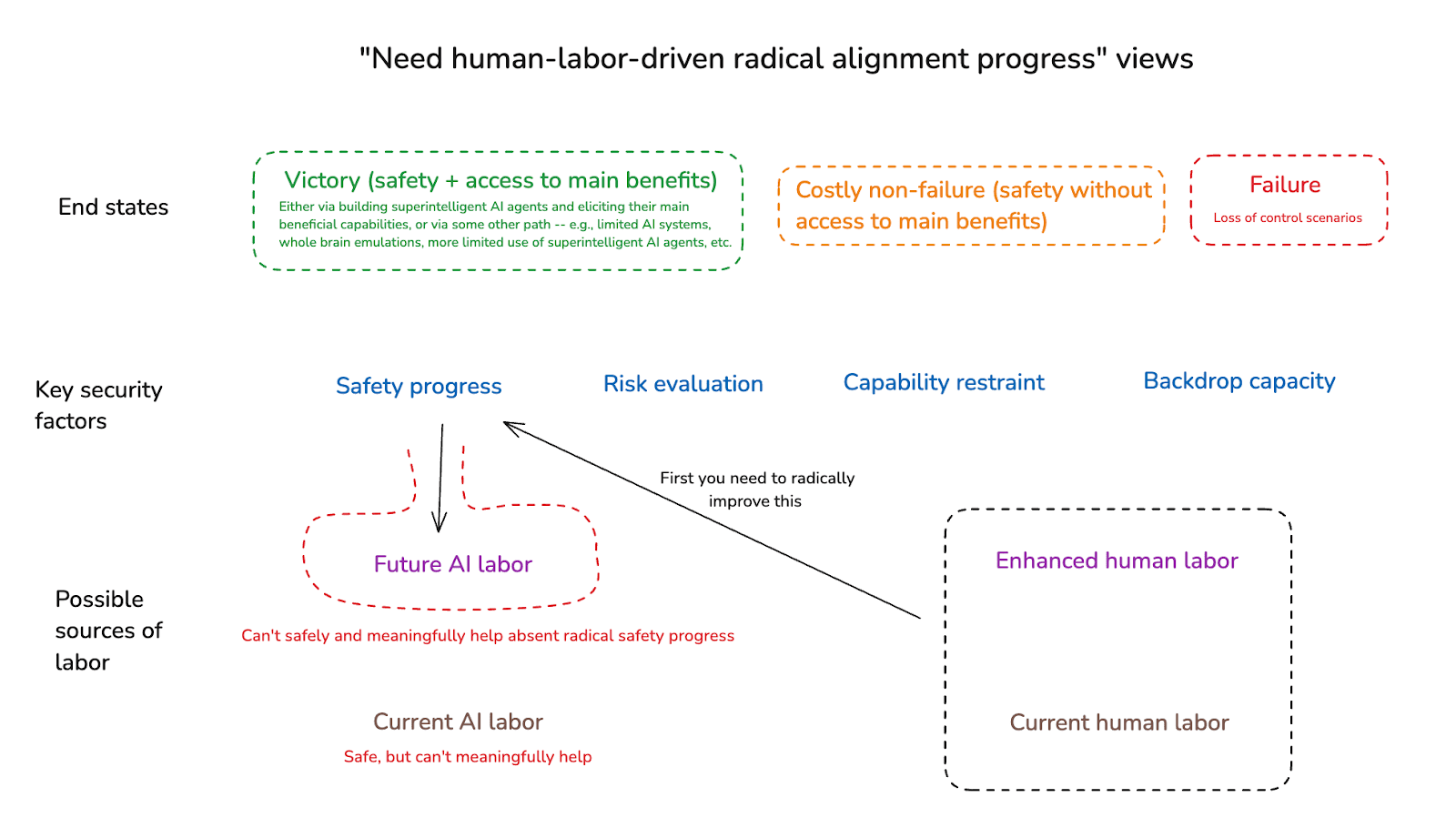
We can also distinguish a sub-type of this sort of view – namely, one on which unenhanced human labor also isn’t enough to meaningfully help with alignment (though: maybe it can help with other security factors).18 On these views, we will specifically need to unlock enhanced human labor, before we can make enough alignment progress to safely and meaningfully benefit from advanced AI labor. And because unlocking enhanced human labor will likely take a while, we will likely need some serious capability restraint (e.g., a sustained global pause) in the meantime. (This, as I understand it, is the rough view of the leadership at the Machine Intelligence Research Institute.19)
I’ll call these views “need enhanced-human-labor-driven alignment progress” views. Thus, in a diagram:
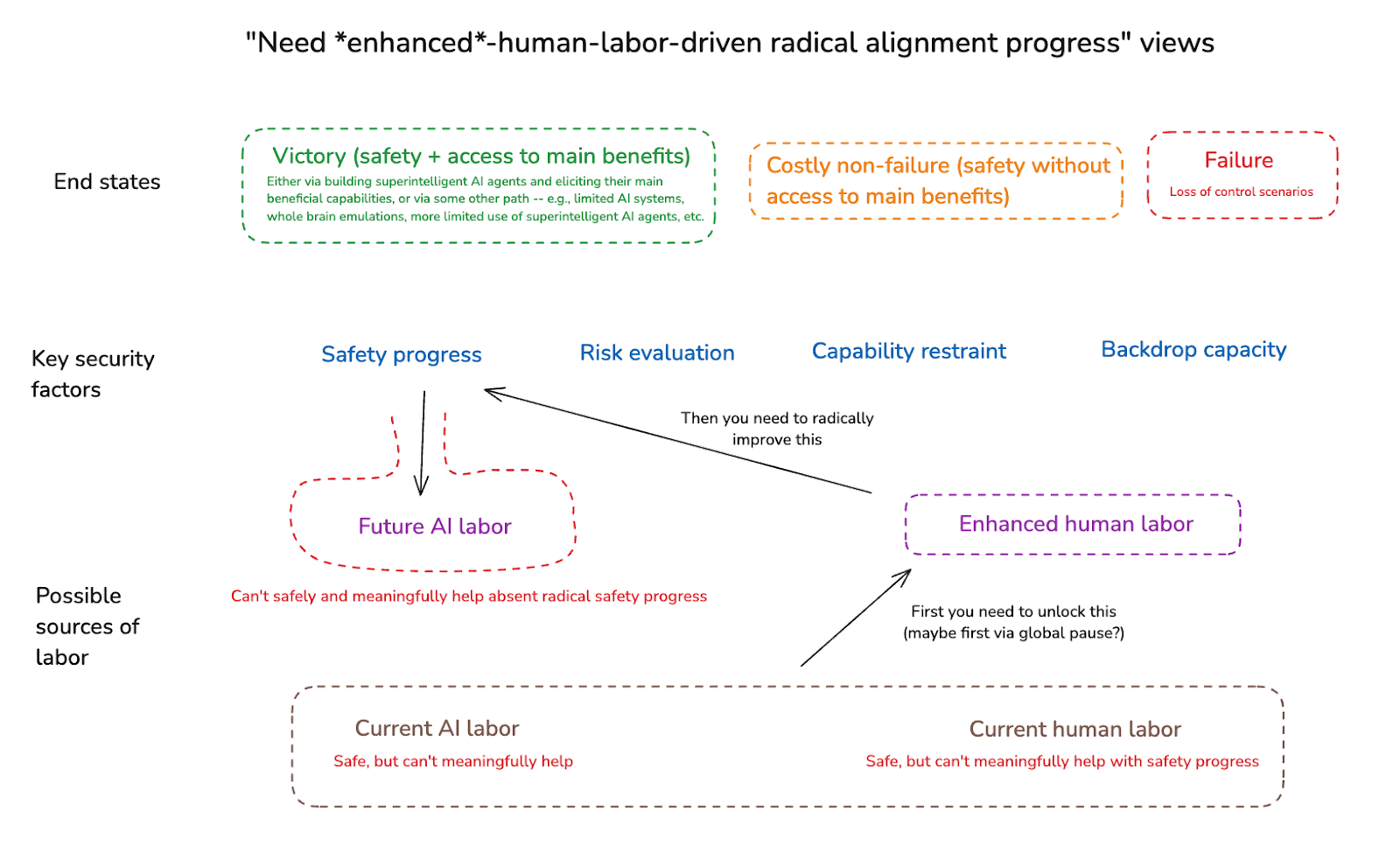
Below I’ll discuss the sorts of objections that motivate views like these. For now, I’m flagging them, centrally, in order for the contrast to help bring the substance of “AI for AI safety” into clearer view. That is: AI for AI safety argues for a more direct role for the “future AI labor” node, even absent radical, human-labor-driven safety progress. In a diagram:
2.3 Contrast with a few other ideas in the literature
I’ll also briefly note a few other contrasts with related ideas in the literature,20 notably:
- D/acc: “AI for AI safety” is closely related to what Buterin (2023) calls “d/acc,”21 which focuses on differentially developing beneficial (and in particular, in Buterin’s framing, “defensive”/“decentralized”/“democratic”) forms of technology relative to harmful forms.22 And we can view the interplay between the two feedback loops discussed above through a similar lens – that is, the goal is to differentially direct the glut of productivity that AI progress makes possible into the AI safety feedback loop, relative to the AI capability feedback loop. But Buterin is interested in differential technological development very broadly (not just AI-driven technological development), with respect to a wide array of issues (e.g., Covid, authoritarianism, etc); whereas I’m specifically interested in AI labor being applied to improving the security factors that help with addressing the alignment problem in particular. And this narrower focus makes clearer how a beneficial “feedback loop” might get going.23
- Automated alignment research: As I noted above, automated alignment research is an especially important form of AI for AI safety (and one I’ll analyze in detail in the next essay); but AI for AI safety covers a variety of other applications as well.
- Pivotal acts: Some approaches to AI safety attempt to identify some “pivotal act” – i.e., an action that drastically improves the situation with respect to AI safety – that we use AI systems to perform.24 This is similar to “AI for AI safety” in its central focus on advanced AI labor – that is, first one gets access to some kind of pivotally useful AI system, and then one “saves the world” from there. But even assuming the world needs “saving,”25 I think that thinking in terms of discrete “pivotal acts” can easily mislead us about sorts of improvements to our security factors required in order for the world to get “saved.” In particular: those improvements can result from a very large assortment of individual actions by a very large number of different agents (and/or non-agentic AI systems), no individual one of which needs to be dramatically pivotal (we might call this a “pivotal act by a thousand cuts”).26
3. Why is AI for AI safety so important?
“AI for AI safety,” then, is about safely using AI labor to improve our civilizational competence with respect to the alignment problem, without first assuming the need for radical, human-labor-driven alignment progress. And I hope it’s clear why, if we can do this, we should. To do otherwise, after all, would be to give up on a source of labor that could provide meaningful help. And not just any source. Rather: in the sorts of transformative AI scenarios we’re considering, AI labor is increasingly the central driver of productivity and progress across our civilization. Of course you’d want to use it for AI safety applications, too – if you can. And not doing this would be a kind of “reverse d/acc” – i.e., differentially slowing down safety-relevant aspects of the economy.
But I think the urgency and importance of “AI for AI safety” – and especially, of automated alignment research – becomes even clearer once we bring to mind the AI capabilities feedback loop I described above. That is: AI developers will increasingly be in a position to apply unheard of amounts of increasingly high-quality cognitive labor to pushing forward the capabilities frontier. If efforts to expand the safety range can’t benefit from this kind of labor in a comparable way (e.g., if alignment research has to remain centrally driven by or bottlenecked on human labor, but capabilities research does not), then absent large amounts of sustained capability restraint, it seems likely that we’ll quickly end up with AI systems too capable for us to control (i.e., the “bad case” described above).
Of course: it may be that, unfortunately, automated alignment research isn’t viable, and avoiding failure on the alignment problem does in fact require large amounts of sustained capability restraint. I’ll discuss various concerns in this respect below; and I’ll discuss this kind of restraint in more detail later in the series as well. Indeed, I think capability restraint remains extremely important even if automated alignment research is viable. Especially on hard problem profiles, we will still need as much time as possible.
But I am sufficiently optimistic about automated alignment research (especially if we actually try hard at it), and sufficiently worried about the difficulty of achieving large amounts of capability restraint (e.g., sustained global pauses), that I think we should approach strategies that focus solely on capability restraint, and/or on human-labor-driven forms of alignment progress, with a large burden of proof. That is: given our current evidence, I think we would be extremely foolish to give up, now, on using frontier AI labor to help with alignment (and with all the other aspects of our civilizational competence). To me, this looks like giving up pre-emptively on the most powerful tool in the toolbox (albeit, also: the most dangerous), and the one most likely to make a crucial difference. Maybe, ultimately, we should do this. But not, I think, on the basis of the existing objections to e.g. automated alignment research; and especially not without having made an extremely serious effort at actually doing automated alignment research well. My next essay explains my view here in more detail.
4. The AI for AI safety sweet spot
I also want to highlight another concept that I find useful in thinking about AI for AI safety – that is, what I call the “AI for AI safety sweet spot.” By this I mean, a zone of capability development (and safety progress) such that:
- Frontier AIs are capable enough to radically improve the security factors above, if relevant actors can succeed at eliciting these capabilities.27
- Disempowering humanity is not an option for these AIs, given our efforts to restrict their options in this respect (call such efforts “countermeasures”).28
Thus, in a diagram:
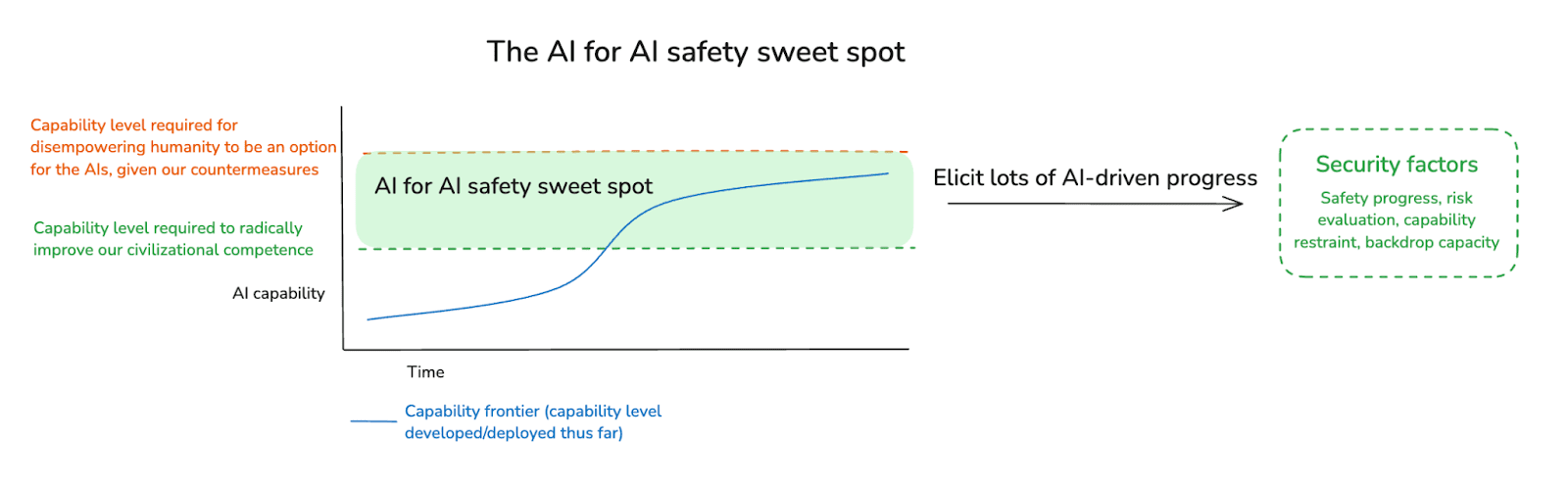
The AI for AI safety sweet spot is important, I think, because it’s an especially salient target for efforts at capability restraint:
- That is: to extent one has a limited budget of capability restraint, applying it once you’re within the AI for AI safety sweet spot, relative to beforehand, makes it possible for the time you buy to go towards radical, AI-driven improvements to our civilizational competence; whereas this is less true of earlier “pauses.”29
- Whereas applying capability restraint later means working with AI systems that are in a position to disempower all of humanity – a scarier position (more on this below).
Note that in principle, different security factors might have different sweet spots – e.g. maybe the capability level required to use AIs to help with coordination is lower than the level required to use AIs for alignment research.30 And note, also, that you can expand the AI for AI safety sweet spot by improving your countermeasures – and that AI labor can help with this.
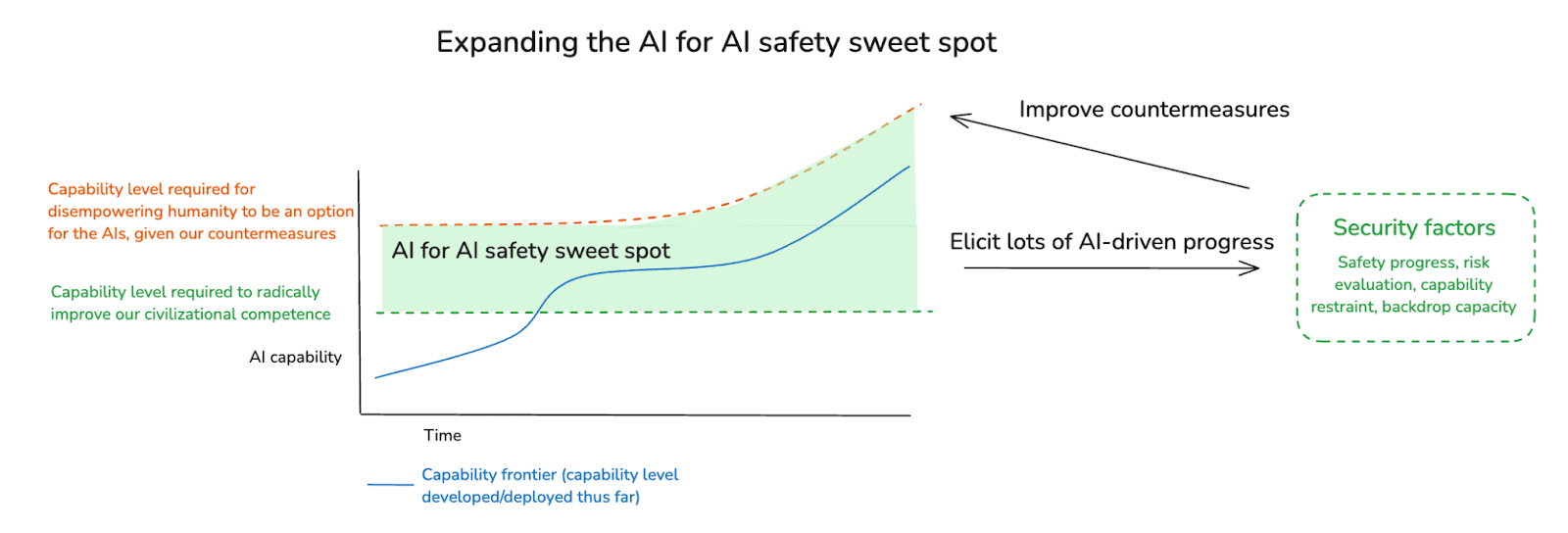
Indeed, some strategies in the vicinity of “AI for AI safety” have roughly the following structure:31
- Step 1: Get to/create the AI for AI safety sweet spot.
- Step 2: Stay there for as long as possible.
- Step 3: Be able to elicit the useful-to-safety capabilities of frontier AIs.
- Step 4: Do a ton of AI for AI safety.
- Step 5: Hopefully things are a lot better after that.
Of course, all of these steps may be quite difficult. That is, step 1 may require significant investment in countermeasures; step 2 may require significant capability restraint; step 3 requires adequate success at capability elicitation; and step 4 requires adequate investment by relevant actors.
And in addition to being a highly useful zone to spend time in, the AI for AI safety sweet spot is also a much scarier to zone to spend time in, relative to earlier points, because frontier AIs are closer in capability to systems with options to disempower humanity (indeed, they may only lack such options in virtue of our countermeasures), and they are likely capable enough to drive rapid progress in frontier AI capability, if applied to the task.
Also: note that it’s not actually clear that we do have a limited budget of capability restraint. To the contrary: one can easily imagine the reverse – i.e., that earlier efforts at capability restraint make later efforts easier (because, for example, you’ve gotten practice with the relevant sorts of coordination and coalition-building; because you’ve started setting up relevant forms of infrastructure; because you’ve changed what sorts of policies seem like live options; etc). Indeed, strategies that involve racing to the brink of destruction, while claiming that you’ll hit the brakes at the last possible second, justifiably invite skepticism – about whether brakes will in fact get pulled, and in time; about the momentum that all-out-racing beforehand will have created; and so on.
Overall, then, I don’t think there’s any kind of knock-down argument for focusing efforts at capability restraint on the AI for AI safety sweet spot in particular. But I think it’s worth bearing in mind as a possibility regardless.
4.1 The AI for AI safety spicy zone
Can we expand the AI for AI safety sweet spot to include full-blown superintelligent agents – i.e., agents that are safe because they don’t have any options for disempowering humanity? In a later essay, I’ll discuss some of the key difficulties with relying purely on option control in the context of superintelligences32 – difficulties that make me expect that motivation control will eventually need to play at least some role in ensuring safety. But I don’t think this is totally obvious.
Assuming we can’t rely solely on option control all the way up through superintelligent AI agents, though, then at some point (if we’re building superintelligent AI agents at all – recall that we don’t have to), we’re going to need to exit the AI for AI safety sweet spot. Importantly, though, this doesn’t mean that “AI for AI safety” is no longer viable. Rather, we just need to have made enough progress on motivation control to do it safely – and we need to keep making adequate progress in this respect as the capability frontier advances.33
Let’s call this sort of capability level the “AI for AI safety spicy zone.”
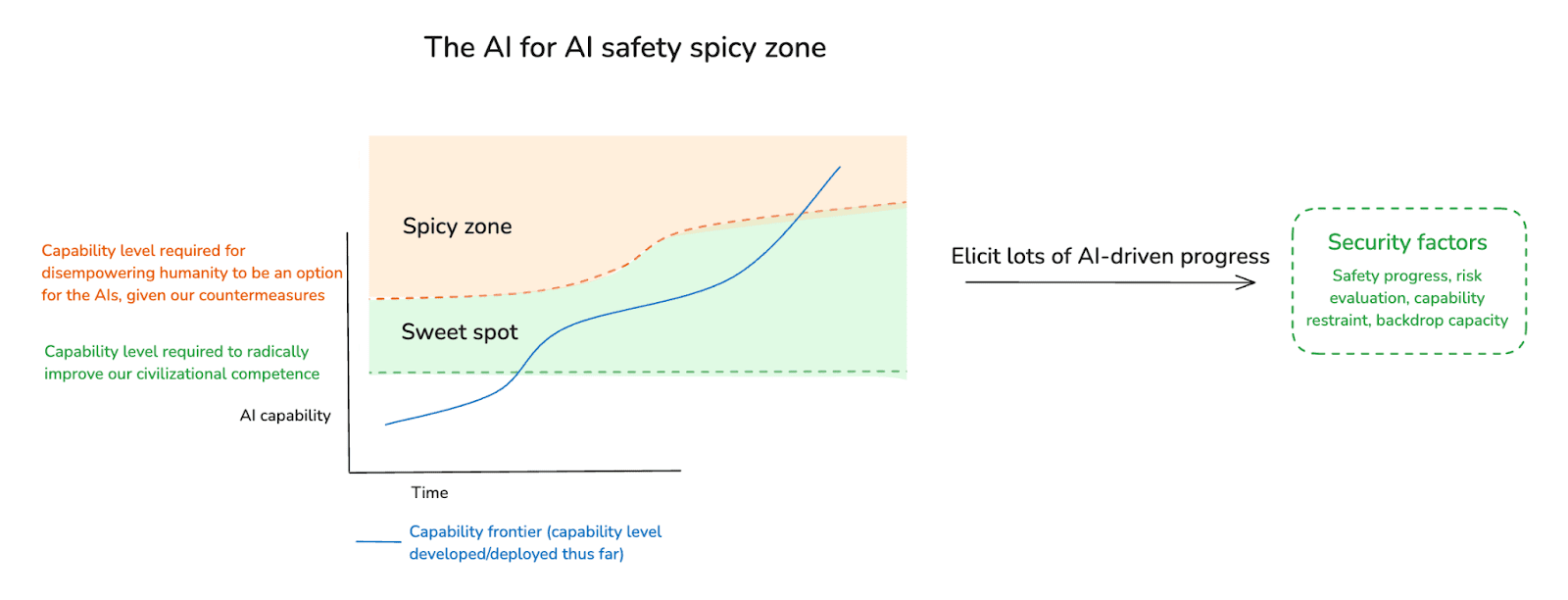
I’m calling this zone “spicy” because it involves entering what I called, in the appendix of my second essay, a “vulnerability to motivations” condition. That is: AIs, at this point, are in a position to disempower humanity, and we are relying on them to choose not to do so. This is a much scarier position to be in than one in which the AIs have no such option.34
Note, though, that as I discussed in my second essay, the vulnerability at stake in the AI for AI safety spicy zone still comes along a spectrum. In particular: it increases when AI systems can disempower humanity via more paths, more easily35; when smaller numbers of AIs can do it, with less coordination; and so on.36
4.2 Can we benefit from a sweet spot?
Will we be in a position to benefit from an AI for AI safety sweet spot? It’s not all clear. Here I’ll note a few salient worries. (And note that these worries can apply to milder versions of the “spicy zone” as well.)
The first is just that: there won’t be a sweet spot at all. That is: by the time frontier AIs are capable enough to radically improve our civilizational competence, they’ll also be in a position to disempower humanity, even given our countermeasures. Call this a “no sweet spot view.”37
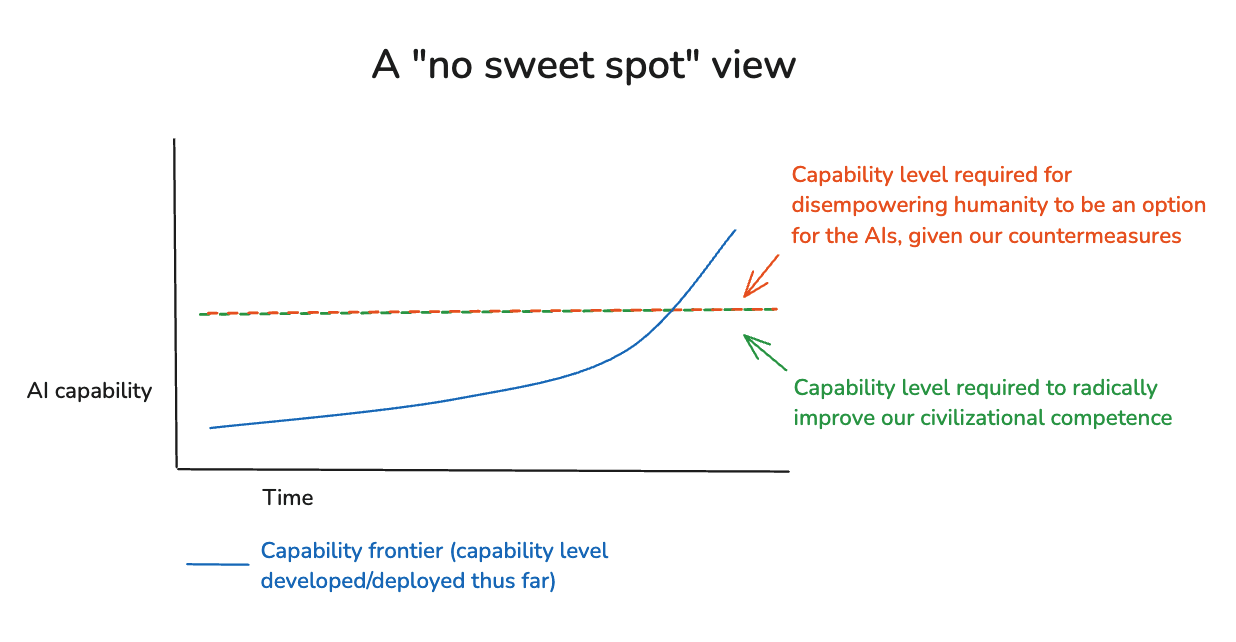
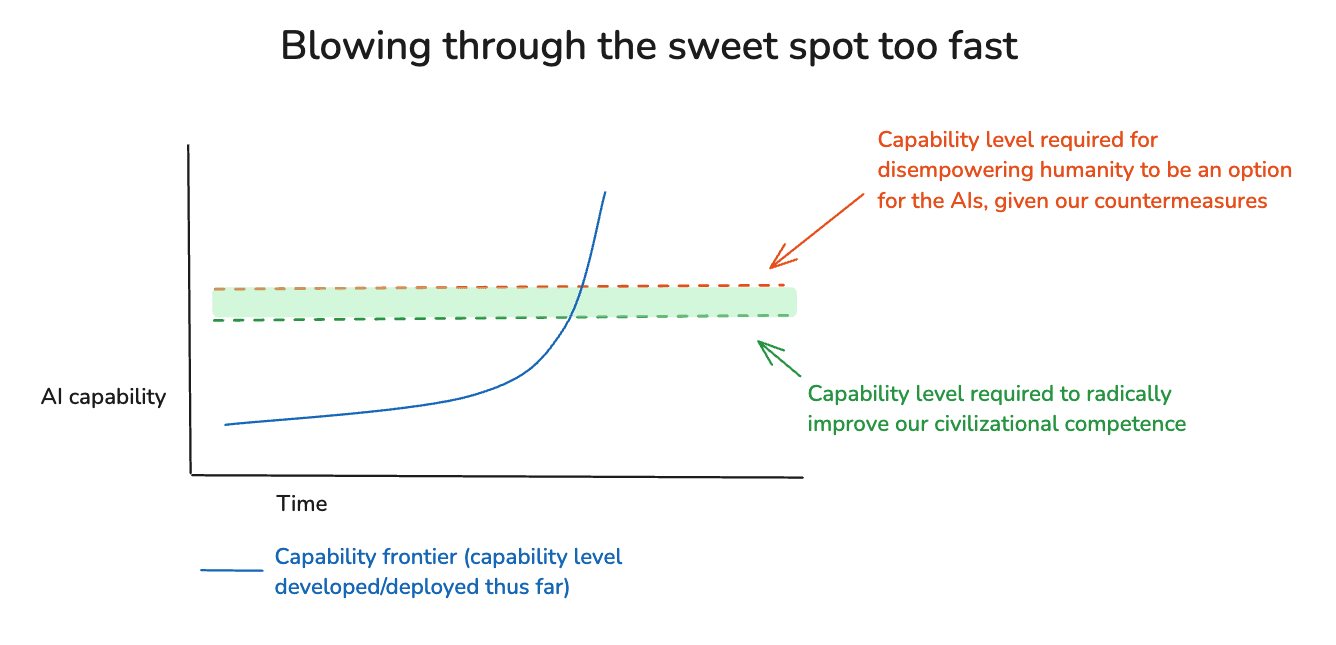
Alternatively: you might think that there will be some sort of sweet spot, but that it will be too narrow-a-band given how fast the capability frontier will be advancing. Different versions of this concern can give different amounts of weight to (a) the size of the sweet spot, (b) the default speed of frontier AI progress, and (c) our ability to slow down if we try, but the broad theme is: we’re going to blow through the sweet spot so fast it doesn’t matter. Thus, in a diagram:
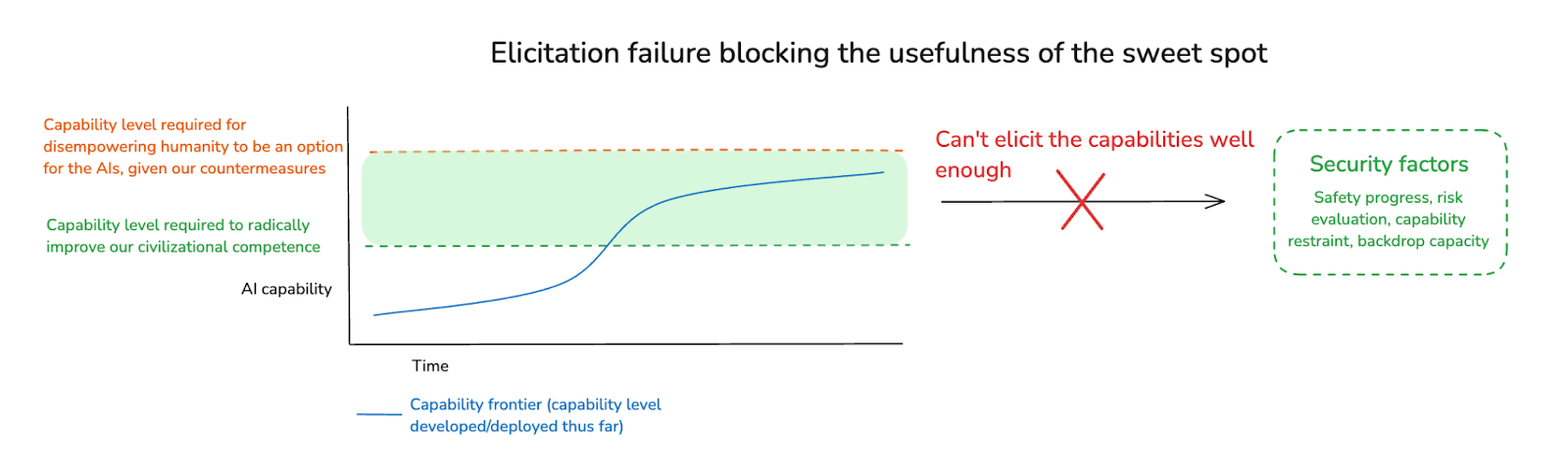
Finally, you might think that there will be a large enough sweet spot to spend meaningful time in, but that we’ll be unable to usefully elicit the capabilities of the AIs in question. Thus, in a diagram:
And we can imagine a variety of other concerns besides.38 Indeed, these concerns tend to mirror the core concerns about AI for AI safety more generally. Let’s look at those more directly now.
5. Objections to AI for AI safety
What are the main objections to AI for AI safety?
I’ll note three core objections that seem to me more fundamental; and then some other objections that seem more practical (which isn’t to say they aren’t serious).
5.1 Three core objections to AI for AI safety
The three core objections to AI for AI safety, as I see them, are:
- Evaluation failures: We won’t be able to elicit the sorts of helpful-to-AI-safety task performance we want out of AI systems capable of that task-performance, because we won’t be able to evaluate well enough whether that sort of task performance is occurring.
- Differential sabotage: Power-seeking AIs will actively and differentially sabotage helpful-to-AI-safety work, relative to other sorts of work (for example, work on advancing frontier AI capabilities), because they won’t want us to succeed in our AI-safety-related goals.
- Dangerous rogue options: AIs capable and empowered enough to meaningfully help with AI for AI safety would also be in a position to disempower humanity. So we would need to already have achieved substantive amounts of alignment in order to use them safely.
I think all three of these objections are serious concerns. And they’re interrelated. For example: weakness in our evaluation processes makes sabotage easier. But they’re also importantly distinct. For example: some evaluation failures don’t arise from differential sabotage, and these have importantly different properties (more in my next essay).
These three core objections can arise, in various guises, with respect to any application of AI for AI safety. But the specific form they take will differ depending on the application in question. For example, the sort of dangerous rogue options at stake in (3) might vary depending on the application.
5.2 Other practical concerns
Beyond these three core objections, we can also note a variety of other concerns about AI for AI safety – concerns that focus less on whether AI for AI safety is viable in principle, and more on whether or not, in practice, we would do it right. Of these, I worry most about the following (but see footnote for a few others39):
- Uneven capability arrival: the sorts of capabilities necessary for AI for AI safety will arrive much later than the capabilities necessary for automating capabilities R&D, thereby significantly disadvantaging the AI safety feedback loop relative to the AI capabilities feedback loop.
- Inadequate time: Even setting aside uneven capability arrival, by the time we’re in a position to use AI systems to meaningfully help us with AI safety goals, there won’t be enough time left before the AI capability feedback loop pushes us into catastrophe.
- Inadequate investment: In practice, relevant actors and institutions won’t devote adequate resources to AI for AI safety relative to other projects and priorities.
I think that these more practical concerns are real and important as well. And here, too, their specific form and force can vary based on the application in question.
In my next essay, I’ll look at these objections – both the more fundamental objections, and the more practical objections – in more detail. And I’m going to focus, in particular, on their relevance to the application of AI for AI safety that I view as most important: namely, automating alignment research.
Further reading
On the structure of the path to safe superintelligence, and some possible milestones along the way.
Examining the conditions for rogue AI behavior.
Introduction to an essay series about paths to safe, useful superintelligence.
I think people generally use the term “alignment research” in a way that covers both motivation control and local forms of option control (e.g. oversight and monitoring; and not: hardening the broader world), and I’m going to do this, too. And I’m going to include wh ...
This also includes identifying and developing more safety-conducive routes towards capability progress – including, e.g., routes that don’t rely on agentic systems; routes that proceed via new and more verifiably-secure paradigms, etc.
Thus, as I discussed in my last essay: this is the waystation that OpenAI’s old “superalignment” team was focusing on – see e.g. discussion More
This is a form of non-local “option control,” but it still falls under “safety progress” on my definition. And note that “backdrop capacity,” discussed below, intersects in important ways with hardening the world to AI attack.
Though note that not all the effects of this on the strategic landscape are necessarily positive. Thus, for example, some of the less aggressive forms of “mutually-assured AI malfunction” involve different actors being a ...
This could include gathering and processing vastly larger amounts of information than humans have hitherto been able to process.
See Davidson (2023) for more here.
See Karnofsky (2022) for more.
See e.g. Lukas Finnveden’s discussion of “AI for epistemics” for more.
Though: this is one of the scariest applications of AI for AI safety, and worth special caution.
See e.g. Amodei’s “Machines of Loving Grace” for some discussion.
Though of course: AI could also degrade our backdrop capacity in lots of ways as well – and in scenarios with a fast and disruptive transition to advanced AI, we might expect a lot of this, too.
Though: note that not all scary AI scenarios involve this feedback loop. For example: the creation of the AI systems that disempower humans might be driven centrally by human labor.
I think I first heard the AI safety issue framed as a race between these two feedback loops from Carl Shulman.
Though: note that to the extent that we end up relying heavily on restraining further increases in frontier AI capability, the AI safety feedback loop also won’t be able to benefit from more capable forms of AI labor, and so the “feedback” aspect will be corre ...
See e.g. Leahy et al (2024) for an example: “The iterative alignment strategy has an ordering error – we first need to achieve alignment to safely and effectively leverage AIs… Fundamentally, the problem with iterative alig ...
Or at least, unenhanced human labor of the form that will likely, in practice, be brought to bear.
Lizka Vaintrob and Owen Cotton-Barratt also have a forthcoming piece on a topic closely akin to “AI for AI safety,” which offers a perspective quite similar to my own -- except targeted at existential security more broadly, rather than AI risk in particular.
See also Clifford (2024) on “def/acc.”
D/acc is thus a particular implementation of what Bostrom (2002) calls “differential technological development.” See also these notes on the topic from Michael ...
That said, the more we focus on “backdrop capacity,” and include human labor in addition to AI labor in the picture, then AI for AI safety and d/acc become more similar (though d/acc is still concerned with a broader range of technological issues, not just the alignment problem).
See e.g. the strategy outlined in MIRI’s 2017 fundraiser update, and Yudkowsky’s discussion More
I think talk of “pivotal acts” often brings in an implicit assumption that the default outcome is doom (hence the need for the world to be “saved”) – an assumption I don’t take for granted. But we can remedy this issue by focusing, in particular, on problem profiles ...
This is a point from Christiano (2022): “No particular act needs to be pivotal in order to great ...
And in particular: if they’re willing to devote large amounts of compute and other relevant resources to the project – though I won’t take a stand here on how much is necessary.
I.e., they don’t have options for disempowering humanity that would succeed with non-trivial probability. That is, in the taxonomy of vulnerability conditions I of ...
Though of course, the usefulness of our AIs comes along a spectrum, and we should be trying to do as much AI for AI safety as we can, at every step along the way.
Thanks to Owen Cotton-Barratt for discussion.
This is the sort of strategy that I associate with e.g. Shlegeris and Greenblatt here
For example: applying option control to superhuman strategies requires access to superhuman forms of oversight and monitoring.
Plus, as in the case of the AI for AI safety sweet spot, we need adequate elicitation ability.
Though obviously, relying on our countermeasures to ensure this condition is its own form of scary as well.
Because the availability of more such paths makes it harder for an AI’s “inhibitions” to rule out all the available options, and higher probabilities of success make it easier for lower-levels of “ambition” to justify going for it anyways.
And in my opinion, arguments about AI risk too often focus on the maximally spicy case (i.e., the case of AIs that are in a position to disempower humanity extremely easily via a wide variety of paths).
In the diagram, I’ve put the two lines in the same place; but in principle, the capability level required for disempowering humanity might actually come earlier than the capability level required to radically improve our competence. H/t Owen Cotton-Barratt for discussion.
For example: we might worry that it will be too difficult to tell when we’re in the sweet spot (h/t Catherine Brewer); or we might worry that relevant actors won’t invest enough resources into benefiting from the sweet spot.
We might also worry about:
Cover: The idea of “AI for AI safety” will provide cover for people to push forward with dangerous forms of AI capability development.
Complacency: ...