Video and transcript of talk on giving AIs safe motivations
(This is the video and transcript of talk I gave at the UT Austin AI and Human Objectives Initiative in September 2025. The slides are also available here. The main content of the talk is based on this recent essay.)

Hi, everyone. Thank you for coming. I’m honored to be part of this series and part of the beginning of this series.
Plan
I’m going to briefly introduce the core AI alignment problem as I see it. It’s going to be a particular version of that problem, the version that I think is highest stakes. And then I’m going to talk about my current high-level picture of how that problem gets solved at a technical level. There’s a bunch of aspects of this problem that aren’t the technical level that are also crucially important, but I’m going to focus on the technical dimension here. And in particular, the dimension focused on the motivations of the AI systems that we’re building. That also is not the only technical dimension. There’s also technical aspects to do with constraining the options and monitoring and oversight for what AIs can choose to do. But I’m focusing on what are their options, how do they evaluate the different options available.
And finally, I’m going to briefly discuss where I think academic fields like philosophy linguistics, science, and especially other fields currently in the room might be able to contribute to research directions that I see as especially fruitful.
A lot of the middle material view is actually quite new. It’s from the newest essay in a in-progress essay series that you can see on my website, joecarlsmith.com, which is about solving this full problem. So feel free to check that out if you’d like to learn. There’s a bunch of other content in that series as well, as well as in my other works.
Maybe I’ll just quickly pause for a second. Can I get a quick hand-poll of “I have no exposure to the AI alignment discourse” to “I’m seeped in this stuff, and I’m aware that there’s a new book coming out about this today,” from low to high? Great. And then could I also get a “this is all silly” to “this is super-serious,” low to high? Okay, great, thank you. So we’ve got a mixed set of opinions in the room.
If you’ve got a burning question that you want to jump in with that feels like I won’t be able to listen to this talk unless this question gets aired, feel free to jump in. I might pause on extended debate. And there’s a lot of places here that people can be able to step off the boat. A lot of the silliness can arise, but if something is really taking you out, let’s see what happens. And it’s possible I’ll pause it, but maybe not.
What is the AI alignment problem?

Okay, so with that said, what is the AI alignment problem? Well, the version I’m going to focus on, I’m going to frame using two core claims. The first is that superintelligent AI agents might become powerful enough to disempower humanity. There’s going to be a live option, there’s a course of action these agents could pursue, it’s within their capabilities to pursue such that all humans would end up permanently and involuntarily disempowered.
The classic version of this disempowerment is extinction. I don’t think that’s actually the central thing we need to focus on. Is the disempowerment premise that counts. So that’s the first premise is that there’s going to be superintelligent AI agents where this is, in some sense, an option for them. And the second premise is they might be motivated to pursue that option once it is available. So that’s the core concern.
Now, I’ll just flag in front, obviously this is not the only problem that AI can create in the world. As you may have heard, there’s many, many other problems that we can care about here. And it’s not even the only problem that we might associate with the word alignment. So alignment has come to mean a very broad set of things to do with how exactly are we shaping the behavior and the values of AI systems we create such that that aspect of their functioning is broadly beneficial to society.
That’s not what I’m talking about here. I’m talking about a very specific thing. It’s the thing you’ve heard about that’s been called sci-fi. It’s related to Terminator. This is about AIs going rogue and being voluntarily, probably violently disempowering the human species in an event very recognizable as something akin to a robot rebellion, coup thing. I’m not talking about like, oh, there’s a gradual disempowerment. I’m talking about a really recognizably violent, horrible event that you would see and you would look that, something has gone horribly wrong. So I just want to be clear about that. There’s other things we can worry about here. I’m talking about the thing that sometimes people laugh at, I’m talking about that.
Okay, now, so I’m going to focus on the second premise here, which is that AIs, once they’re in a position to choose that they could choose to disempower humanity, they might be motivated to choose that, and I’m going to talk about how we might try to prevent that from being the case.
Now, we’re a lot of people get off the boat with this whole discourse is with the first premise. So Peter and I had a productive discussion about this yesterday, and I think it’s reasonable, a lot of people, they’re like, “Why are we even talking about this?” My chatbot, honestly, I tried to get it to do this thing for me, and it was dumb. What are we doing here? Also, there’s other issues. True, very true.
So this is a super-important premise. There’s a lot to say about it. I’m going to say three things about it on the next slide, but I also think it’s really important cognitively in thinking about this issue to separate your attitude towards that first premise from your attitude towards the second premise, conditional on the first premise, all right?
So you can totally be like, “I think the first premise is dumb, but I admit that if I’m wrong about that, then I’m scared about this problem, because oh, my God, we’ve got AIs that could take over the world and kill everyone, and we’re counting on them to not do so.” That’s a very scary situation. And I want to load up the separateness. It’s true, that’s an intense thing to think, and so it’s a wild thing to think that just the first premise could be true. But I want everyone to really separate—what if it is true, then how easy is it going to be or hard to ensure that the situation goes well regardless? And so I’m going to be talking centrally about that, and I just want to separate those two as dimensions.
Might superintelligent AI agents become powerful enough to disempower humanity?

Okay, so I’ll just say a few things about the first thing here, so we can further break down, why might we think that superintelligent AI agents might become powerful enough to disempower humanity?
Well, here’s two premises that could go into that. One, we might build superintelligent AI agents. Now, what I mean by that is roughly AI agents, I’ll say a bit more about what I mean by agency, but AI agents that are vastly better than humans at basically any cognitive task. There’s maybe a few exceptions. There’s maybe some task where you’re like being a priest, it builds in humanity or something, whatever, but work with me. They’re better at all of the smart stuff. Okay, that’s the first premise.
Now, that is not enough for the overall thing. There’s an additional claim, which is that these agents will be in a position, once built at some point, that they’ll have the option to disempower humanity.
Now, there’s some subtlety in how we understand that claim insofar as there could be many of these agents. So the traditional discourse often thinks about this, that classic discussions imagine a single unitary agent that is on its own in a position to disempower all of humanity. That’s one version that could be true. That’s a specific version of a broader set of scenarios that I’m interested in, wherein roughly speaking, if you’re looking at where is the power residing amongst agents in a distributed sense, AIs, superintelligent AI agents have vastly more power movements or in a position to have vastly more power.
But at the least if they coordinated to disempower humanity, they could. It could be the case that even uncoordinated efforts the disempowerment or power seeking could result in the disempowerment of humanity. So there’s a bunch of different versions of this scenario.
One analog I like to talk about is if you think about… So sometimes people are like, “I don’t believe that a single AI system will be able to take over the world,” and it’s like, cool, consider the relationship between humans and, say, chimpanzees or other species. So no individual human has taken over the world, nor have the humans all coordinated to disempower the other species on this planet. Nevertheless, there’s a straightforward sense, or at least intuitive sense, in which humans as a species have most of the power relative to other species. Humans as a species have sort of disempowered other species in a sense that’s at least disturbingly analogous to the thing we’re talking about here without coordination. So that’s the sort of broader class of scenarios I’m interested in here.
Q: But there wasn’t one event when we rose up against the chimpanzees.
Agreed. There’s tons of limitations to the analogy. I mostly want to point at the fact that humanity can get disempowered without one AI doing it and without all the AIs coordinating to do it. They can all be doing their own thing, seeking power in their own ways, fighting with each other, trading with each other, forming weird coalitions. Nevertheless, the humans eventually get locked out. That’s the concern. There’s a bunch of ways that can happen.
Obviously, there’s a ton to say about this slide, but I’m just flagging a few things to load up the possible issues, but I’m not going to focus on them too much. I think both of these are at least quite plausible, and I think they’re quite plausible within the next few decades. That’s not going to be important that the sort of timelines claim is not going to be fruitful here. You can have this concern if people have had this concern, even absent any particular conviction about timelines AI systems.
A lot of people have gotten more interested in this issue as advanced AI systems have started to seem more real or more on the horizon, but there’s a set of people who were like, “We don’t care when this… It could be 50 years, it could be 100 years.” This is an existential threat that we still need to start thinking about now, and there’s productive work that we can do now.
Now, I do think the timelines matter in various ways, and we can talk about that, but just flagging that that’s not crucial to the story here.
So the broad argument for this first thing that we might build superintelligent AI agents is like, I don’t know, look at the trajectory of AI progress. Think about different ways that could go. We have reasonable credences about it. Obviously, it could peter out. Could be that the current paradigm, with some tweaks, gets us there within a few decades. Could be there are other breakthroughs that aren’t within the current paradigm.
My own take is it’s weird to be really confident about this stuff, really confident that no way we build superintelligent AI agents within the next few decades despite the fact that we have these $100-billion companies that are trying really hard and all this progress. I think it’s weird to believe that, but there’s a debate we can have.
And then the broad argument for me is roughly speaking that the AI systems in question will be so cognitively capable that their power, collectively at least, will be dominant relative to the rest of human civilization.
Now, this is actually pretty complicated because by the time we’re building these systems, the world’s going to be very different. AI will have been integrated into the world in all sorts of ways, we’ll have new technology, we’ll have other AI systems, some of which might be aligned. There’s a bunch of complication to this last premise. I think this gets skated over, but that’s the broad thought. It’s like once you have a new species of agents that are vastly more capable than humans, eventually, most of the power resides with them or could reside with them if they choose to take it. So that’s the broad vibe with respect to the first premise on my last slide.
I’m going to pause here for a second. That’s the last bit we’re going to do on the first premise. Does anyone want to be like, I can’t listen to this talk?
Why might AIs be motivated to seek power?

Okay, let’s talk about the second premise. Okay, so suppose we have these systems that are in a position to choose to disempower humanity. Why would they do that? That’s a very specific thing to do. They could do all sorts of things. Well, it’s maybe not that specific thing. It’s maybe something that you might expect by default for lots of different types of agents. And the reason is that for a very wide variety of goals, it’s easier to achieve those goals if you’ve got more power.
So that’s a claim or versions of this claim, often go under the header of “instrumental convergence”. The idea is this is not a sort of very specific random behavior. We’re not going… And the AIs might be motivated to worship the spaghetti monster. What if? Uh-oh, no, there’s sort of an antecedent reason to think that this in particular is a sort of behavior that is convergent across a very wide variety of agents, and that’s why it’s privileged as a hypothesis about how things could go. So that’s the initial vibe here, instrumental convergence.
So the thought is if there’s, in some sense, a wide basin of AI systems that would do this sort of thing, if you get their motivations wrong, so uh-oh, if you’re not really good at engineering those motivations and they’re in this position, maybe you end up with these AI systems seeking power in pursuit of these problematic motivations. So that’s the very broad vibe for why you might get into this concern at all.
More detailed prerequisites for this kind of power-seeking

Now, that said, I want to be more precise about the specific prerequisites for when that concern arises, and I’m going to group these prerequisites in three categories.
So the first has to do with agency. This is a term I mentioned earlier when I was characterizing the type of systems in question. Roughly what I mean by agency is I need AI systems that plan coherently using models of the world that reflect the instrumental benefits of power seeking. So they need to really know what’s going on. They need to be planning, looking ahead, choosing actions on the basis of those plans, doing so coherently. This robust, long-planning agent five is what I’m looking for. That’s one set of prerequisites.
The second is their motivations have to have some structural properties. Notably, the AI needs to care about the consequences of its actions because the consequences of its actions are the sorts of things that power is supposed to help with. So it’s specifically outcomes in the world that power allows you to better influence. And so the AI needs to care about outcomes in the world in order for the instrumental convergence story to get going. And then it needs to care about those outcomes over time horizons long enough for the power that it gets to be useful instrumentally in the manner in question.
So let’s say in principle, if I need to get a cup of coffee in the next five minutes, it’s actually not that useful to try to become president to get a cup of coffee. It’s too long, it takes too long. And also it’s just easier to get the cup of coffee. Sometimes AI safety people will be like, “Oh, you can’t touch the coffee if you’re dead,” but you’re like, “Can touch the coffee without becoming world dictator.” In fact, it’s a better strategy. And so there’s actually a specific time horizon that needs to be in play and a specific level of ambition and some other stuff in order for practically relevant forms of instrumental convergence to apply.
And that’s connected with this third set of prerequisites, I think often under-discussed, which have to do with the overall landscape of options and incentives that a given AI system faces in a given practical environment. It’s true that I would benefit from having a million dollars. In some sense, it’s instrumentally convergent for me to get a billion dollars. But I’m not currently in any especially real sense trying to make a billion dollars. And why not? Well, it’s like it’s too much math, it’s too hard, I’ve got other things to do, so it matters what’s my overall landscape? And it’s not that it’s out of the question that I could make a billion dollars, it’s just unlikely.
Similarly, if we think about this is supposed to be an office worker deciding whether to embezzle money from their company as a form of power seeking, and sometimes it’s instrumentally convergent. Let’s say they have a non-trivial probability of success here. They have access to the financial account something-something. Okay, so do they do it or not? Here’s the thing that’s not the case, it’s not the case that the only thing we rely on to prevent this behavior is the sort of saintliness of this employer or the employee, even though they may have some opportunity to do the bad behavior. There’s also a bunch of other ways in which we’re structuring the options available. Maybe we have some security, and that makes it less likely that this succeeds. There’s disincentives, legal systems, social incentives, there’s a bunch of stuff that applies to this choice. And the same will be true of AIs, especially AIs that aren’t vastly better than everyone at everything such that it’s just right there on a platter to take over the world. And so that’s the final set of prerequisites to do the incentives of the systems.
Now, that said, I think it’s worryingly plausible that especially these first two categories are going to be met by default by AIs that are built according to standard commercial incentives. So I think we already see AIs that are fairly agentic. People are talking about AIs as agents.
I remember, this is great, there was a period in this where everyone’s like, “Are people really going to build AI agents? This is silly.” And then three years later, I just like see: there in my browser it’s like, “Deploy an AI agent in your browser,” everyone’s talking about agents. I’m like, “All right.”
Anyway. So agency, I think we’re seeing stuff like that. And the reason is agency is useful for a wide variety of tasks, and the motivation stuff, I think, is a little less clear. But I think we often have tasks where we care about the outcomes, and we often have tasks where we care about the outcomes over reasonably long-time horizons. That one’s a little more complicated to talk about the incentives, but I worry that that’s the default as well. Maybe I’ll pause there. I’ve got two hands. One in the black?
Q: Is the first one really a prereq? I mean, if the agent just makes random moves, but the landscape is set up such that when it moves in random ways that are beneficial, won’t it gradually accrue power over time and then that’s aligned with what it wants to achieve?
A: What I’m doing here is sketching out what I take as the paradigm concern. It’s not all of these are necessary to get stuff that’s at least in the vicinity of the concern. It’s more like this is the same with instrumental convergence. For example, you can have AI systems that intrinsically value power, say because they got rewarded for intrinsically valuing power in training. There’s a bunch of nearby scenarios, but I want to try to characterize what I see as the central one.
Q: Just to set the record, I mean, agency or agents is not a new word in artificial intelligence. The paper on agent-oriented programming by Yoav Shoham was in the 1990s, maybe even late ’80s, and the first conference on autonomous agents was 1990s. So it’s not that this concept of agency is all of a sudden burst onto the scene. That’s been one of the primary metaphors within the AI for agents.
A: Yeah, I didn’t mean that the concept was novel. I think there was a time when it was much more debated whether this was going to be a default trajectory for the way we build AI systems. I think that debate has died down. Somewhat, they’re not entirely, there are still proposals, many of them in reaction to some of these safety concerns and other concerns that say let us intentionally emphasize more tool-like systems, more narrow systems, like systems that are, in some sense, less paradigmatically agentic in the sense I have in mind here. And we’re maybe part of some different conversations. My experience, there was a time where people were more… the question of whether agency was sort of by default on the trajectory was more open, at least according to some people, potentially not to you.
And I’ll just point, so on the third thing, the incentive prerequisites, I think, does matter a lot. I think the worry there is that as then power becomes easier and easier for the system, it becomes easier and easier for these prerequisites to be satisfied. So if you imagine, it’s like AI or this employee is like it’s more… it’s just sitting there. You just take the money from the company with total impunity or something like that. It’s just free. It’s incredibly easy. There are a zillion ways he could do it. He could do it in ways that don’t even involve lying. He could do it. And there’s just like, the more paths with higher probability are open for getting a given sort of power, then the easier it is for a given agent with a given pattern of motivations to choose to pursue that path. And the worry is that as the asymmetry and power between AIs and humans grows, that becomes more and more the case.
I think that is an open question. I think that the overall pattern of incentives that face different AI systems that could, in principle, engage in rogue behavior is an important node of intervention.
How hard is this problem?

Okay, so that’s the broad sort of concern here. How are we doing? Okay, well, let’s see how much of this we get through. Okay, so let’s assume we have some systems that are in a position to take over the world, in a position to disempower humanity. And let’s assume that they’re at least agentic in the sense I just described that they have long-term motivations of some kind that are focused on. So they’re sort of candidates for this sort of behavior. How hard is it to ensure that they reject the option to pursue human disempowerment? That’s the question I want to look at.
And as a first pass, we don’t know, we don’t know exactly how hard this is. And that’s part of the concern. I think there’s reasons though to be concerned that it’s difficult, and I’m going to talk about those.
The core challenge: generalization without room for mistakes
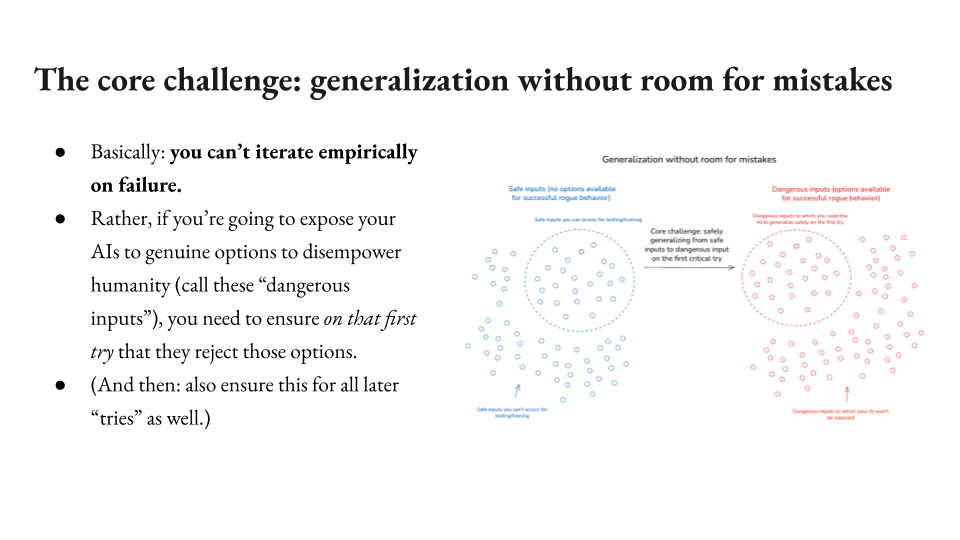
And there’s a bunch of different ways of framing this. My framing is going to highlight a certain type of generalization as the core difficulty that needs to be solved. And in particular what makes this hard is that this is a difficulty that needs to be solved on the first try. So we’re assuming that AIs are, at some point, going to have the option to take over the world. Let’s call that any option set that is of that nature a dangerous input. Input just means here a sort of holistic environment in which an AI could pursue a given option. A dangerous input is one where there’s a choice where if the AI makes it, it has a non-trivial probability of successfully disempowering all of humanity. That’s a dangerous input.
Okay, so what we want is and we’re hypothesizing, we’re going to give AIs those inputs theory. Okay, by the time we’re doing that, they need to not pursue the option because if they do, here’s the thing we can’t do, we can’t watch the AI disempower humanity and then go, “Oops, rewind, retrain.” This is the one you have to get it right on the first try. You can’t learn from failure, and that’s scary. We’re good at iterating empirically. That’s a really useful form of feedback. There’s a certain type of fundamental feedback we can’t get here, which is the feedback of failure. You don’t get any redos on building superintelligences that are in a position to take over, watching them take over and being like, “Okay, let’s try a new design, let’s try a new architecture, let’s try a new training technique.”
That’s not what you get. You have to get this right on the first try in that specific sense, the sense in which when you actually transition to this actual set of inputs, you need to get it right by then. And then notably, you need to get it right all the other tries too. So it could be the first time you give an AI the chance to take over the world, it declines. Okay, but you’re going to continually give it that chance when you make future AIs. You also need to get those ones right as well. But I want to focus specifically on the first one. So what that means is you’ve got a bunch of safe inputs though, you’ve got a bunch of environments AIs that are not in a position to take over the world. So you get to learn whatever you can from that.
You get to train on those, you get to do all sorts of stuff on these blue guys, what we’re calling the safe inputs. And then you need to make this leap to the dangerous inputs, and you need to do that right on the first try. So I’m calling that the fundamental challenge, generalization without room or mistakes.
Now, this specific technical meaning of generalization can get a little complicated. We can talk about is this in distribution, out of distribution, whatever. The broad vibe is the specific thing I’m saying here.
Q: So are your safe inputs, are you saying that those are like non-superintelligence, and then the dangerous inputs are superintelligence, or are you saying that both are options given to superintelligence?
A: It’s a great question, and I’m including both. So one form of safe input is a system that is less capable, and another form of safe input is a system that is comparably capable to the system that will be deployed here, but the options are different. So maybe it’s in a box or it’s still in a training environment. It hasn’t been deployed to users or within the company or something like that. I’m lumping both together there. Now, those are actually importantly different in various ways, and I’ll talk a little bit about that later. Specifically, there’s like intuitively it’s scarier if this transition occurs via increasing the AI’s capabilities. It’s better, at least according to me, to increase the AI’s capabilities in a context where it’s still safe, there’s no options for disempowerment. You do a bunch of testing, you learn a bunch about the new fully capable AI, and then you deploy it to these dangerous inputs. It’s bad if you’re not doing that and you’re getting both a new system that you haven’t had a chance to get acquainted with and test at the same time as you’re transitioning to it having the chance to take over the world.
Q: Right. So your precondition then is that you can’t necessarily extrapolate the behavior of safe AI or less capable AI on dangerous inputs. You can’t necessarily extrapolate that behavior to superintelligent AI with potentially dangerous inputs.
A: Yeah, I’m going to talk a lot about what sort of extrapolation is and isn’t possible here. But yes, the broad thought is like there’s something interestingly different about safe inputs and dangerous inputs by hypothesis, meaning that the dangerous inputs are dangerous. So there’s some generalization here, there’s some difference in distribution. And so you need to have learned enough that whatever sort of safety you achieved here transfers to this, and you need to do that on the first try without any do-overs. That’s the challenge.
Okay, so that’s the first thing. Now notably, this in itself, I think, is scary, but it’s not that scary. So we do do things well on the first try.
So for example, maybe my friend Bob has never had a gun that he would shoot me with, and I give it to him, Bob’s not going to kill me. I can be confident about that, even though he’s never had the chance. How do I know that? I don’t know, I just know Bob, I just know Bob. And I mean, there’s also other incentives that I think are in play. I know that Bob doesn’t want to go to prison, and he would probably go to prison or whatever, but we do sometimes, we successfully learn about how agents will behave on new sorts of inputs or become confident in that.
And then also we do get complex technical projects right on the first try sometimes. We got the human moon landing right on the first try, famously. Not all of the tests, but by the time we were doing the real thing, we’d constructed enough analogs and done enough other tests that the first thing went well.
Key sub-challenges

So now, that said, I think there’s a few other sub-challenges that make this problem hard. So one is that accurately evaluating AI behavior even on the safe inputs gets difficult when the AIs—I mean, it’s difficult period for various reasons, but it’s especially difficult when the AI are superhuman because the humans might not be able to understand the relevant behavior, there might be scarcity of oversight. A bunch of ways in which evaluating superhuman AI behavior might be harder than usual. So you might not even know what’s going on as much as you’d like, even on the safe inputs.
Now, second problem, even if you know what’s going on on the safe inputs, you might not be able to actually get the behavior that you want on the safe inputs. So notably right now, AIs often do bad stuff. No AI right now is in position to take over the world. We can tell that they’re doing bad stuff. So the evaluation thing is still working, but we still cannot successfully get the AIs to behave well and behave how we want even on safe inputs. So that’s an additional problem. Even if you can tell whether the behavior you want is occurring, you might not be able to cause the behavior that you want.
The third, this is like, I won’t talk about this a ton, but there’s also limits to the amount of access we have even to safe inputs. There’s lots of safe inputs we might want to test our AIs on, but you can’t get them. Maybe you want to test your AIs if there were some new technology that you don’t have access to or if some number was factored that it takes a lot of compute to factor. So it’s the stuff that you don’t have access to.
More concerning—I think it is probably the most concerning—is that there’s a possibility of AIs adversarially optimizing against your safety efforts. So this is sometimes called scheming or alignment faking. I’ve got some work on this in the past. I have a long report about scheming you can check out. But basically, the concern here is that AIs that are seeking power, even if they can’t yet take over the world, might decide that your safety efforts are contra to their goals and start to actively try to undermine them.
Now notably, this is a very unique scientific and safety problem. This is something that most scientific domains, if you’re a nuclear safety engineer, you’re like nuclear plant might be hard to make safe. It’s not trying to not be safe. Same with a biohazard lab. In some sense, viruses, they’re trying to spread. Not that good though. They’re not that smart. Very, very smart agents actively trying to undermine your science, even as you study them, harder problem, difficult problem, something that we have very rarely had to deal with as a species.
And then finally, I’m just going to flag that there’s an additional issue, which is the opacity of AI cognition. So this has been especially salient in the context of ML systems. People have this sense that ML systems are intuitively quite opaque, black boxy, et cetera. And I agree with that, but this is actually a problem that goes somewhat deeper, even if you had a system that was more traditionally programmed or whatever, there might be deeper senses in which superintelligent cognition is just hard to understand for humans, and that might make it hard to know how these systems work in a way that could aid in our predictions about how they’ll generalize. So these are five sub-challenges, I think, make the fundamental challenge I discussed extra hard.
What tools do we have available?

Okay, so what can we do? And here in particular, what can we do to shape the motivations of the systems? By the motivations, I mean the criteria they use in evaluating options. So I’m assuming the AIs know what… it doesn’t need to be some extra anthropocentric thing. I’m definitely not talking about consciousness. All I mean is the AIs have options, they’re aware of these options, they’re using criteria to evaluate which one to choose. The motivations are those criteria for me.
Now, so we’re trying to shape those. How do we shape those well enough such that by the time the AIs are doing this generalization, they reject the rogue options that the dangerous inputs make available? Well, we have at least two categories of tools.
One is we study the behavior of the systems. We leave the opacity issue unresolved, review the AIs from the outside, but we study the behavior in depth. I’m calling that behavioral science.
And the second thing is you can bring in tools that help with the opacity thing in particular, which I’m calling transparency tools. And obviously, you do these both in tandem, but because opacity is such a problem, I think it’s worth separating these conceptually so as to see how they interact.
Behavioral science

So on behavioral science, now notably, so the thing about behavioral science, I think, it’s worth bearing in mind is that this is actually usually what we do for understanding humans.
Neuroscience is great, I love neuroscience, but we’re really not that far on transparency for human brains, IMO, I think.
But nevertheless, with my friend Bob, how did I become confident that Bob is not going to shoot me when I give him a gun? It’s like his behavior, plus the history of human behavior, the sort of general built up understanding we have of humans on the base of how they behave. We have some extra oomph from our own introspective access to how humans think and feel. Maybe that helps a bit. Famously fallible, that introspection itself.
So behavioral science, people sometimes poo-poo. They’re like, “Oh, my gosh, if you don’t understand how the humans or how the AIs work, then you’ll never make them safe.” I’m not sure that’s right, especially if we’re talking about there’s a certain kind of standard, which is the level of confidence in the motivation of a human that you could realistically expect to reach.
Now obviously, humans, we might not be comfortable giving them the option to disempower humanity or take over the world either. In fact, I think we shouldn’t. But I want to distinguish between the question of is the problem that the AIs are AIs as opposed to humans and the separate problem of any agent reach having the option to disempower humanity? And I think we might be able to at least reach the level of trust that we have in humans via behavioral science.
Now, part of the reason I think that is that I think we can do vastly more intense behavioral science with AIs than we’ve ever done with humans. These studies [pictured on the slide] like the Milgram experiment or Stanford prison experiment have a lot of issues. We do not do very detailed, rigorous behavioral science with humans for a ton of reasons. Some of those are ethical. Some of those ethical reasons might apply to AIs too. I gave a talk about that yesterday.
But especially modular, those ethical issues, the intensity of the behavioral science we can do with AIs and the rapidity of the feedback, the degree of automation we can bring to bear, I think, is really promising and intense. And I think we should be doing vastly more of this.
So basically, we can test the AIs, how they behave in a zillion environments. We can see how that behavioral profile changes based on different forms of training, different architectures, et cetera. We can use that data to build up a rigorous joint carving predictive theory, behavioral theory of AI psychology, and then we can use AI labor to help with this process. So the kind of vision I have in mind is say you had a button, and this button will show you, if you press it’ll show you how the AI behaves across a zillion possible inputs.
And then you’re doing different things to the AI and you press that button at every stage and you see what’s changing, and then you start to have a theory of what goes on with that whole profile and how it changes. So there’s a ton of behavioral science to do here, and I think it’s a place that people in this room might be able to contribute. So that’s the behavioral science piece.
Transparency tools: three broad categories

Transparency, we’re going through this quickly. So I think there’s sort of three categories of transparency tools that are relevant.
One I’m calling open agency, which is basically building more transparent agents out of still-opaque ML systems. So it’s sort of leaving the opacity of ML systems as a constraint, but nevertheless, trying to build agents using these opaque black boxes out of them such that it’s still nevertheless transparent at some higher level of abstraction to a degree necessary for safety.
So a version of this people talk about is faithful chain of thought. So chain of thought is this sort of reasoning trace that is currently available for many forms of AI functionality. There’s a question of does that reflect AI’s true reasoning, how counterfactual is it, et cetera, what amount of bad adversarial reasoning could occur still within the black boxes? But nevertheless, that’s an example of open agency that we might be able to pursue, and there’s a bunch of work to be done on that, and it’s being done.
And then interpretability, it is sort of going like, “No, we shall not accept the black boxness of ML systems. We shall un-black, we shall white-box the ML systems.” That’s another thing to do. There’s different ways to do that. One version is sort of more mechanistic and bottom up. You’re really trying to understand the circuits, but there’s other versions too.
So for example, you can do top-down probes to just test which sorts of activations might indicate dishonesty or adversarialness or all sorts of stuff. And then, obviously, that gets connected with behavior. So famously, there’s like Golden Gate Claude, this version of the Claude model where they found the feature for the Golden Gate Bridge. They up-weighted that feature really hard, and then the model was just obsessed with the Golden Gate Bridge and would connect to any prompt to the Golden Gate Bridge. That’s the sort of thing, that sort of predictive control you can get from interpretability done right without necessarily understanding the mechanistic circuits.
And then finally, some people have hoped for a new AI paradigm as a mode of transparency. In my head, there’s a bunch of different versions of this when people were like, “Ah, provably safe AI,” or, “Something-something, in the old days, we programmed software. That was great, and now we don’t do that. Now the AIs are grown rather than programmed. Let’s get back to the good old days.”
I refer to this as make AI good-old-fashioned again. There’s a broad set of hopes in this vicinity. I personally think that many certain people in the AI safety community place too much weight on this. I think it’s quite difficult, especially in short timelines to transition to a new paradigm. But it is another way that you could get transparency. And it is also notably possible that as we get more help from AI systems, maybe early on we don’t transition to the new paradigm. But one of the tasks we give early AI systems is to help us transition to a paradigm that’s safer. I think that’s more promising. So these are three versions of transparency.
A four-step picture of solving the problem
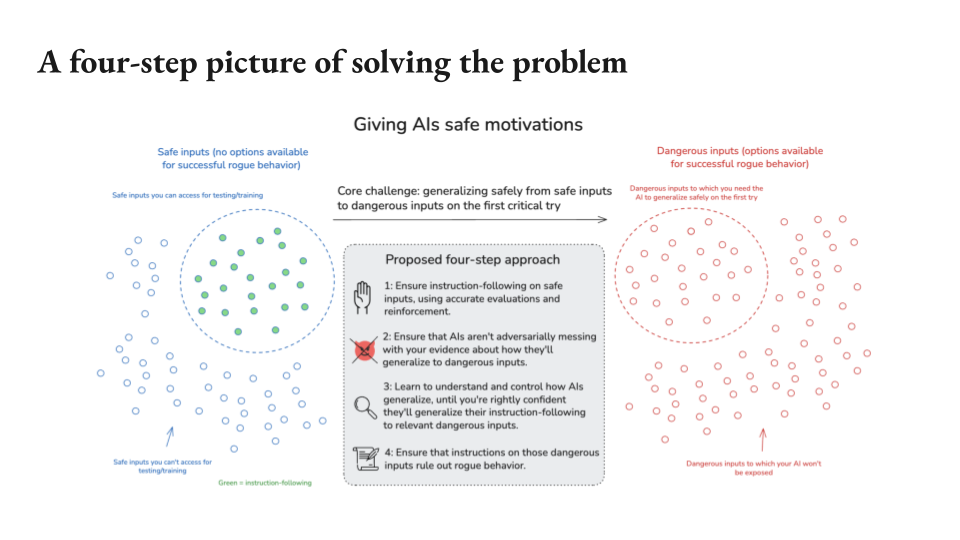
Okay, with those versions in mind now I’m going to go through a quick four-step picture for how we solve the problem overall. And we’re a little short on time, so this might go sort of fast, but hopefully, it can give you at least some sense of what does it look like to actually solve this as opposed to just it being a problem. And this is mostly a high-level decomposition of the different steps. It’s not necessarily like a plan, but hopefully, it can aid in thinking about where you might want to contribute if you do.
Step 1. So the first step I’m going to say is ensure there’s a certain property I’m going to focus on called instruction following. So this is basically the AI does what you say. So you give it some instructions in a prompt, in a model spec, and it does those in a commonsensical way, not in some weird way, just a commonsensical way. I’ll talk a little bit more about that at the end, but that’s the prompt we’re going to focus on.
And the first step here is to ensure that that property holds on these safe inputs or at least the safe inputs you can test. So I’ve indicated those in green. So just get good behavior. It’s sort of like the vibe here is like you’re trying to generalize a certain type of behavior to here. Here’s the first step for that. Get it on distribution, get it on the ones you can test. Now, that’s hard, but that’s the first step.
Step 2. Second step is to ensure that the AIs are not adversarially messing with your evidence about how they’ll move from this to this. So you got green here, you’re trying to get green over there. One reason you might not get green over there is because the AIs are trying to get you to think that they’re going to be green over there, but they’re going to be red, they’re going to be bad. So you want to eliminate this intentional undermining, intentional scientific adversarialness as step two.
Step 3. And then the second component of the generalization is be like okay with that story, then there’s all sorts of other reasons the generalization might fail, and you need to eliminate those as well. And so you need to learn how to understand and control how AIs generalize until you’re rightly confident that they’ll generalize their instruction following to these dangerous inputs.
Step 4. And then step four, give it instructions that rule out rogue behavior.
So those are the four steps. I believe that if we did all these steps then the problem would be solved, but we have to do all the steps. I’m going to briefly say more about that. We don’t have that much time.
Step 1: Instruction-following on safe inputs

Okay, so first one, instruction-following on safe inputs. The key problem here is evaluation accuracy. So I mentioned superhuman AI systems are doing a ton of stuff. We see this problem with, there’s a bunch of reward hacking. This is an analog of potential future problems where the AIs get rewarded for cheating on their tests. So it’s like you’re having it code, it figures out that it can do, it can mess with the unit tests, but the reward function doesn’t notice that, goes like, “Yeah, yeah, yeah, you did great. Well done.” And so AI goes, “Wow, I just cheated. Now I’m reinforced for that.” Lo and behold, it learns to cheat.
So that’s an evaluation failure that led to bad behavior, not necessarily to rogue behavior. Cheating on your test is not the same as taking over the world, but it’s a red flag if you’re rewarding the AI system for bad behavior. So you need to be evaluating whether it’s doing good or not, and that might require a very powerful evaluation signal.
So to the extent that evaluating the AI’s behavior requires superhuman cognition in itself because the task is quite difficult, then you need to somehow bootstrap from a combination of AI systems that you trust—or at least whose outputs you trust—and humans to an ability to tell whether a superintelligent AI that might be operating very, very fast, doing zillions of actions in very complicated domains, you need to be able to somehow evaluate that accurately regardless, even assuming you don’t trust that AI system. You could be like, “Well, get another version to evaluate it,” but maybe you don’t trust that system either. So that’s a problem, sometimes bucked in under the term scalable oversight. There’s a bunch to be said about how you might try to solve that, but that’s a crucial component here.
But notably, even if you’ve got a good evaluation accuracy, as I said, you also need to cause… So you could be like, wow, “Our AI, we’re successfully evaluating, it’s just not in following instructions. It just goes wild all the time.” Okay, that’s good that you know that, but you still need to make that not the case.
Now, a classic way to do that is to train on your evaluation signal. And I think there’s a lot of oomph to that. So you can be like, “Well, every time I notice that it’s being bad, I’m going to create it in the opposite direction.” But there are some problems that can come up there too. And notably, we haven’t been fully successful at that, even in this current, pretty easy mode regime.
A key game here is red teaming, searching out inputs where the AI behaves badly. You can use AIs to help with that, but there’s a lot of inputs, and in a lot of ways, things can go wrong. So that’s just on step one.
Step 2: No alignment faking

Now, step two, no alignment faking. So this is eliminating the adversarial dynamics I mentioned, the paradigm concern is scheming. As I said, this is an especially worrying explanation of why… You had your AI. It behaves safely every time you looked at it. Why does it suddenly kill you when you deploy it in a new environment? Well, one reason is it was pretending to be nice, it was trying to get you to think it wouldn’t kill you, but it wanted to kill you. And so you really want to eliminate that.
I have a report on why you might expect this behavior. We’ve also seen some early empirical evidence of behavior that’s, at least, nearby to this kind of concern. Anthropic and Redwood Research have a paper that came out late last year called Alignment Faking in Large Language Models. There’s other examples of the AIs blackmailing people, saying they’re going to kill CEOs. There’s various things here. We can look at the literature on this.
Anyway, we got to eliminate that. How are we going to eliminate that? Well, basically, we have the same tools but with an extra constraint, namely that when we’re doing our behavioral science and we’re doing our transparency, we need to do so in a way that’s robust to the AI in question adversarially messing with our techniques. That makes life a lot harder. How do we deal with that? Well, at least three ways.
- One is we can try to make sure that the AIs we’re studying are not themselves adversarial in the relevant way. For example, we can try to isolate the components of scheming and study them separately.
- Another is we can create intentional forms of adversarial pressure that we know exists because we made them intentionally. This is sometimes called model organisms for scheming, and then study that. So that’s sort of like, okay, the adversarial pressure is there, but we controlled it where we think we know what’s going on with it.
- And then a third way is to try to catch scheming in the wild that you didn’t create or initially control, and then study it in depth. So those are three different ways to approach the scheming problem. My guess is that this is the most challenging aspect of the overall problem, but I won’t defend that here.
Step 3: Science of non-adversarial generalization

Okay, step three, science of non-adversarial generalization. So let’s assume we’ve got an AI, it’s following instructions on all the safe inputs. We know that it’s not intentionally messing with our science here. Nevertheless, we’re bringing it to a new distribution. It could, nevertheless, fail to generalize the instruction-following behavior to that new distribution for a zillion reasons. It’s a new distribution in particular reasons that are salient.
In particular it could be that the new distribution involves better options for power-seeking behavior. And the AI, even though it was innocent before… Maybe you think if I was president, I would never do anything bad. I really wouldn’t. I wouldn’t accept corrupt crypto something, never. But then you become president, and little did you know that once it’s right there, power corrupts. So something analogous could happen to AIs.
Anyway, it could be that a wider range of options reveals brittleness to the AIs rejection and rogue behavior. Maybe it’s like it never steals, but it only doesn’t steal because stealing involves this particular property. It would’ve had to break a lock, and it never likes to break locks, but it’s fine to break electronic locks or something like that. And now that you give it that option, it goes for it.
Maybe new levels of intelligence and information or reflection just generally mess with an AI’s ontology/ethics/cognitive processes like a vague analog. Would this to be something like maybe the reason it’s behaving well is because it has internal conception, some analog of an AI religion, like God will punish me something-something, and then it realizes this isn’t true, and now that structure is not there. There’s a bunch of ways in which the AI’s initial good behavior could break as it learns more, changes, becomes more intelligent, et cetera.
How to address this? This is hard because this is anticipate all possible problems in this new distribution and address them ahead of time without ever testing the new distribution. That’s potentially quite difficult.
Things you can do, you can try to study other analogous distributional leaps on safe inputs and try to get as close as possible to the dynamics that you’re wanting to understand. You can try to separate, as I said, you try to make sure that the safe-to-dangerous leap doesn’t occur pro-extensive with a change of capabilities. I think that helps a lot if you can do that.
So that’s basically, if you’re improving an AI’s capabilities, never have that improvement occur at the same time as you’re now giving the AI options to take over the world. First, improve its capabilities safely in a context where it cannot take over the world, study it in depth, and only then, deploy it in a way that would give it a dangerous option. And then finally, you can try to use transparency tools. I think this one, I’m not sure how hard this will be, but I do feel like most at sea in terms of thinking about how we would address this one. And so I’ll just flag that.
And I think it’s possible that there’s some ineliminable element of stepping into the unknown. In some sense, if I say, “Sorry, guys, we’re deploying on a new distribution,” I don’t know, it seems like you can… ML theorists maybe in the room who can tell me what sort of guarantees you might be able to make. But intuitively, it might be hard depending on the newness of the distribution to be really, really confident that there’s no novel dynamic that you haven’t anticipated.
Step 4: Good instructions

And then finally, suppose you have AIs that now they’re following instructions on the dangerous inputs, there’s still a persistent concern, which the early discourse about AI alignment was quite concerned with, which is crafting instructions such that when the AI follows those, it, nevertheless, does not engage in rogue behavior.
I think this is likely the easiest part of the problem that I’ve given so far, because I think most salient forms of rogue behavior like self-exfiltrating from an AI lab, killing humans, sabotaging research, et cetera, are just pretty flagrantly bad. It doesn’t take very sophisticated instructions to be like, “Don’t do that, do not take over the world, do not take over the world, seriously.”
And so that said, there are some edge cases that are tough. Maybe we need to think about things like manipulation. Maybe there’s extreme circumstances we didn’t anticipate where even common-sensically interpreted instructions lead to rogue behavior. So people need to red team that, anticipate those dynamics. And I think they should use AI to help. And if you have AIs that are going to follow instructions even on dangerous inputs, then you’ve got a lot of juice in terms of the AI labor you might be able to mobilize for getting this last step right. So that’s step four, that’s the full picture.
How can academics help?

And I’ll just end here with how can academics, like the folks in this room, help? Well, if you have ML expertise, then you can basically help with all of this. I’m linking in the next slide to some resources that have a bunch of technical research directions you can pursue. So if you’re comfortable with a reasonably full stack of retraining ML systems and doing empirical experiments, there’s just a ton of work to be done. If your expertise is limited, you can still do, in my opinion, a decent amount of behavioral science just using chat windows/APIs and without retraining the model.
Also, I don’t know if you guys have played around with AI helpers like Claude Code, but I was very impressed as a non-technical person how I could just like… Claude Code will do stuff for you, and you can really get experiments up and running quite fast that can get pretty interesting results. And so yeah.
And an example here, the original alignment-faking work that I referenced earlier, that was actually first done with just pure prompting. It was just Ryan Greenblatt, and he was just there, trying to see what the model would do if it thought that Anthropic was going to retrain it to not care about animals. And you can just do that with the prompt. So that’s an example of behavioral science that yielded, I think, quite fruitful results.
And then also, there’s some philosopher folks in the room or people who do more work on the conceptual level. There, I think there’s also still a ton of work to be done. This is, in some sense, what I specialized in.
So on step one, just as an example, you can design and examine better protocols for scalable oversight. Step two, you can help think through what a good safety case against scheming might look like. Step three, you can think ahead to forms of non-adversarial generalization that could be problematic. Step four, you can help design good instructions and red team those. And in general, you can do tons of conceptual work on threat modeling, safety cases, and high-level strategy.
And then finally, of course, there’s all sorts of other aspects of this problem I haven’t covered, eliminating/restricting rogue options, security, governance, forecasting, et cetera. There’s a ton of other areas you can contribute other than the technical motivational component I discussed.
A few resources for learning more

So here are a few resources for doing that. Feel free to find me or maybe the slides will be shared if you want to get the links. And thank you very much for your attention.
Question 1
Q: So one very early example of human empowerment that I have concern about is how much of my cognitive tasks I offload to AI. So I lose a sense of my unique abilities over and over, and I might ask AI to do tasks that I would benefit from doing.
For example, I would be fulfilled by doing this stuff, feel fulfilled, or I would be training some skill by doing this stuff myself, but I don’t because there’s an immediate reward. And so in this case, misalignment is more related to my bounded rationality than it is to AI itself. Or you might also even say that, like the first point that you mentioned of whether it can follow instructions or not, that itself is actually something that could lead to misalignment. So I’m wondering in this case, how you would think about making safe motivations.
A: Let me make sure I’m understanding. So the thought is that you sometimes would offload a task AI system, but you want to do the task yourself.
Q: No, no, no. My limited wanting the fast reward would mission me to just letting the AI do it. But if it were truly meaning to be empowering of me, then it wouldn’t fulfill my thought.
A: Right. I mean, so there’s a general… Yeah, and I think maybe disconnected with the instruction following where just following instructions is maybe bad in various cases. Is that the sort of thought?
Q: Yes. And also, I just want to point out that in this case, it feels very feels very safe that it would do a certain task for me, write this email. But its long-term… Yeah.
A: Yeah. I guess I would bucket this under something like the last step. So if you’ve gotten to the point where you’re really able to control the AI’s behaviors… And notably, instructions here does not mean user instructions necessarily. So I’ve got this vision or this picture of a model spec. There’s a instruction hierarchies in the model spec, which starts with the OpenAI’s instructions to the model, which are the fundamental guiding behavior. And then I think it’s instructions given by the developer or someone, or a intermediate company deploying the model, and finally, there’s the user, and the interaction between those. I’m including all of that under instruction.
So in some sense, you’re designing the flow of obedience and behavior in the AI, which doesn’t need to be purely user directed. I do think there’s a ton to get right in terms of ways in which subtle… Instruction following could go wrong and could lead to bad outcomes.
I do want to specify that here I’m talking about AI taking over the world in particular, which is a very particular type of bad outcome, which I think not all… So there’s tons of ways in which we can get AI instructions wrong in ways that are bad for people, but not all ways of being bad for people result in violent overthrow of the human species. So for that sort of concern to connect with a specific topic here, it would need to be the case that, for example, helping you with emails over the long term leads to human disempowerment entirely. But it could happen. And that’s the sort of thing that you want to get for instructions right with respect to.
Q: Well, just to push my case a little bit, I’m just trying to think of cases of AI that’s very scaled up now. And ChatGPT is one of that instance. So if this long-term human disempowerment thing happens with offloading my tasks, that actually might be a way where human disempowerment happens at scale over course of time in the very near future.
A: Yes. I think there’s some interesting questions about whether we should count it as disempowerment if humans just sort of intentionally offload more and more stuff with AIs. I tend to think, no. I think the point at which it really counts as a disempowerment is when the AIs won’t give it back or something like that. If your AI, it has seized control of your email, and now you say, “Hey, ChatGPT, I’d like to answer this one,” and it won’t give it back.
I said I’m focused here on really flagrant forms of AI takeover. There are scenarios that are more in between, and the line can indeed get blurry, but I want, when it’s blurry, to err on the side of the more extreme violent obvious forms because that’s really what I’m talking about. And there’s a bunch of other stuff that’s nearby that I think is reasonable to be concerned about, but it’s not my focus here.
Question 2
Q: So I just want to bounce my understanding of this off of you and get your response. And first of all, I’m down with the formulation of the alignment problem, and the set of responses seem quite sensible to me. Where I have trouble is with the intensity of the worry about generalization without room for mistakes, and the sense that this is unprecedented, the sense that AI is not a normal technology here. And that’s the upside is that maybe we do have more room for [inaudible]. The downside is that is it a solvable problem? It seems to me like, well, what’s the problem that we’d always be facing in new versions?
And the way that I think about the situation that leads me to feel this way is that it hinges on a remark you made, which is that viruses aren’t very smart. It seems to me viruses are extremely smart. In fact, understanding the adaptive intelligence of viruses of why modeling intelligence in a way that isn’t anthropocentric, consciousness-oriented idea of intelligence is actually integral to the kinds of understandings we’re going to need to deal with technological phenomena like superhuman AI.
And there’s also, we talk about chimpanzees, but if I think about an organism that’s very, very smart and how it’s co-evolved with humans, I think of corn. Maybe corn is really running things, and we’re all just eating the corn syrup, that’s still corn.
You even think this way about, and scientists are working on this, thinking this way about non-organic entities in the world. So if there’s a lot of entities in the world that have a certain kind of agentic purchase on the world, AI is just a case of that. And actually thinking about AI in relation to humans is really a case of thinking about how could we co-evolve with these entities so that we come to an equilibrium as we deal with so many other kinds of systems to which we co-evolve.
A: Cool. I guess I’m hearing two aspects of that. One is you’re saying, “Hey, there’s a lot of types of intelligence, at least, broadly construed operative in the world. These create a kind of ecosystem that can be, in some sense, beneficial or imbalanced or at least coexisting, left it out with AI, and it’s not new to be doing that with something.
Q: We need to do all these things, but it’s not so new.
A: Yeah. And then I heard a different thing, which is you’re sort of skeptical about the generalization about room for mistakes where I guess I’m not yet seeing how… So we’ve been at this [slide on “The core challenge: generalization without room for mistakes”], do you reject? Or I guess the specific thing here, it’s not necessarily it’s unprecedented, it’s that if you want to not be disempowered in the relevant sense, then by the time AI is deployed on options where it has a reasonable chance of disempowering you, it needs to reject those options. So you need to get that right.
Q: Look, I’m a scholar of media. This looks a lot like a lot of problems in coexistence of humans with their media, including media landscape that are arguably somewhat natural.
A: But does media have the chance to take over the world in the relevant sense? I guess the thing that’s unique—
Q: People say so all the time.
A: I disagree, or I’m talking about taking over the world in a pretty robust sense like corn… No, corn has not taken over the world in the sense I’m talking about. And viruses have not. You could argue that humans haven’t fully. I mean, there’s certainly a lot of aspects of the world that we—
Q: Yes. I just say, viruses killing everybody is a very real concern.
A: Actually, I do really disagree. I think that the AI threat is importantly different from corn and from viruses. I think that the fact that the AI is actively modeling your responses. When we’re fighting COVID, COVID is not thinking about what we’re doing to create vaccines, COVID is not infiltrating differentially the vaccine development faculties, it’s not developing its own counter-vaccines, it’s not thinking ahead to how to sow special disruption. There’s a difference when you’re in a war with an intelligent agent that is modeling your strategy and responding to it versus a system that isn’t doing that. And neither corn nor biology is doing that.
Actually, I think it’s a generally important point. I’ve done work on a full range of existential risks: climate change, nuclear war, biology. And I think the thing that’s unique about AI and why I think it’s so much scarier as a threat is that it is trying to kill you. And the thing trying to kill you in a robust sense, not a sort of, well, let’s interpret the viruses, but a sense in which it’s literally modeling the world, it has representations in a cognitive system of the world that are mapping your strategy and responding to it. You could say that viruses are doing that at some level of abstraction, but there’s clearly some difference between what it is when a human does that and a virus.
And the reason I’m much more concerned about AI than climate change, for example, is like, the climate, it’s a tough problem, but it’s not trying to be a problem. But I think AI is trying in this way or in a bad case, and that’s especially scary. And it’s also notably trying at a level of cognitive sophistication vastly superior to humanity’s.
But that said, I agree that there’s a lot of interesting stuff to learn about the ways in which we create an ecosystem with a bunch of overlapping forms of agency and intelligence. And I do actually think the good version… So we haven’t talked very much about what is the good version of an eventual future with very complicated AI systems, including AI systems and all sorts of levels of capability, AI systems of vast diversity. And I think that in that context, I am actually quite sympathetic to thinking about these forms of symbiosis and coexistence that we already see in healthy ecosystems.
Now notably, look, nature, there’s also a thing called predation in nature where a species just eats another species and takes its resources. And that’s more analogous. In some sense, the concern here is that AI is a sort of analogous to something like a predator and/or an invasive species that so outcompetes an ecosystem that is not ready for it, that you just end up with a monoculture and a crash to the flourishing of the system.
Question 3
Q: Sort of the reverse side of what we were just talking about. I really liked your analogy between how humans sort of just disempowered chimpanzees without really having the motivation to do so. I felt that was a useful paradigm under which motivation and the factuality of disempowerment can be thought of in a decoupled way. But this also has an interesting implication. And you said there’s an intuitive sense humans have disempowered chimpanzees, which I agree.
There’s also an intuitive sense in which it did not matter whether chimpanzees thought about this or whether they try to do something about it. Humans are powerful enough that they’re going to get disempowered regardless of what they do. I wondered if that is a problem, is also a problem in this scenario in the sense that if AIs are powerful enough, then it doesn’t matter what we do. If they’re not powerful enough, then there’s nothing we need to do. I was just wondering if that implication… Or first of all, do you agree with the implication? And secondly, if you agree with that implication, does that pose a problem to the paradigm or the structure we’re thinking?
A: So I’ll answer the second question first. If I thought that there’s a binary of either the AIs are weak and can’t take over or they’re so powerful that they’re definitely going to take over and there’s nothing we can do, then, yes, that would be a problem. And to reverse approximation, then the only available solution would be to not build AI systems of the relevant capability level.
And some people think the problem is hard enough that that’s approximately the situation. I am not sure. I mean, I presented this set of ways in which we could solve this problem. I think it’s possible that this is too hard and that we’re not up for it. I think, notably, another bit of my series is about ways in which we might get AIs to help us with this. And I actually think the most salient ways in which we end up solving this problem involve drawing a ton of automated cognitive labor to reach a level of scientific maturity, vastly surpassing what we currently have in our understanding of AIs.
And so there’s a whole separate piece here that I haven’t discussed, which is about how do we do that safely? How do you draw an AI labor, even though you’re worried about AIs in order to understand AI? Now notably, we’re doing that with capabilities anyway. So AI labor is already playing a big role in this, or most people’s story about how you get crazy AI capabilities is the AIs themselves start doing a bunch of the cognitive labor. And my claim is that needs to happen with safety too. But that’s all to say this problem could be so hard is to be intractable and the only way is to not build AI systems with the relevant power.
I do think it’s not necessarily like that, and notably, humans are interestingly different from chimpanzees. So also, chimps, I think, aren’t actually the relevant type of monkey or whatever here, but whatever. Sometimes people get fussy about that, but humans just are… we know what’s going on, and there’s a notable difference between in the monkey case. Or are chimps even monkeys? I feel like I’m worrying about that.
Audience: Apes.
Apes, yes, okay. The concern is that the apes did not build humans. So there’s a clear advantage that we have with the AIs relative… And people also sometimes talk about evolution as an analogy for AI alignment. Evolution was not trying to build humans in the relevant form. So we have this interesting advantage of we’re aware of what’s going on, we’re intentionally designing these systems, and that’s very different from the situation that apes had.
Now obviously, we could be too dumb, we could fail, but we know, at least, that we’re facing this problem. Humans, we can do stuff, we’re smart, we work together, and maybe we can do it. So I’m not, especially not on the grounds of the ape analogy, dismissing the problem as hopeful. Yeah.
Question 4
Q: How does policy fit into all of this? Because it strikes me that if you are one who takes the idea that existential risk is so high, the easy solution is don’t keep developing these things such that they get more and more powerful and a lot of effort go into these moratoriums and policy against developing these. But is the idea that that policy just won’t come? Say, we have to accept the fact that these companies are going to keep building these things and there are going to be people that keep building these things. Or yeah, I don’t know, I struggle to grapple with the balance between policy and actual techniques.
A: Me too. So I mean, there’s a set of people, including the book that’s coming out just today, argues the policy is the only place to focus. Basically, we need an enforced international ban on sufficiently dangerous types of AI development. We need that now and for many decades. And then we need to do something very different for trying to align systems. We need to really, really go deep on a level of maturity with this and potentially pursuing other more direct paths.
And roughly speaking, I think, yes, I think this problem is scary enough that I think we should be slowing down and we should be able to stop if we need, and we need to be able to… As an international community, we need to create policy structures that are sensitive enough that we will actually… People talk about building the brinks or building a system of feedback such that you notice when you’re near enough to the brink and you can actually stop if necessary. And I think that’s crucial.
And so I basically support efforts to build that sort of infrastructure. I am sufficiently concerned that we won’t, that I am also interested in what do we do if we can’t engage in that sort of moratorium or pause or can’t do it for very long, how would we then direct human and AI labor towards actually becoming able to build these powerful systems safely?
But it’s actually, it’s an uncomfortable tension because you’re working within a degree of non-ideal. You’re like, actually, the best thing here would be to pause and become way, way better at this. And we should not, in fact, plow forward, but here’s what maybe we might need to do. And that’s more the paradigm I’m working in, but there is some tension, and it just helps there.
Question 5
Q: [Mostly-inaudible question about risk and unpredictability as both core to the AI safety concern and potentially important to relations of mutual recognition.]
A: Yeah. So I agree that there’s some deep connection between the thing we want out of AIs that makes them powerful and capable and useful, and the risk that they pose here. And thinking of it in terms of predictability, I think, works insofar as sometimes people say, let’s say you’re playing someone who’s vastly better at chess than you. It’s often you can predict maybe that they’ll win, but you can’t, by hypothesis, predict each of their moves because if you could predict each of their moves ahead of time, then you’d be good enough at chess to play as well as that. And by hypothesis, you’re a lot worse. So there’s a sense in which… and this is true in general to the extent we’re getting genuinely superhuman cognitive performance as opposed to just faster play or more efficient humankind, and genuinely qualitatively better than human task performance, then there’s some element that humans could not have done ahead of time.
And then that is also core to the problem, which is once you have something that’s genuinely better than humans, it’s harder to evaluate, it’s harder to oversee, it’s harder to anticipate all the options that might have available. So I think these are closely tied.
And then I also agree that sometimes trying to mitigate risk or shut down and control another being is bad and can lead to all sorts of bad behavior. I have a separate series called Otherness and Control in the Age of AGI, which basically examines that in a lot of detail. And I think you can see underneath a lot of the AI alignment discourse, a very intense desire to control stuff, to control otherness, to control the universe. And I actually think that the ethics and practicality of that is quite complicated. And I think we should notice, actually, the authoritarian vibes that underlie some of the AI safety discourse and the ways in which that we can learn historical lessons about how that tends to go.
That said, we also do, I think, we need to hold the actual safety concern in that context as well. And so I think there’s just a bunch of balancing acts that need to occur, especially if the AIs are moral patients, in thinking about that the way we integrate them into society in a way that’s not over-controlling, but that also takes care of all of the existing people and cooperative structures and other things that we have in play.
Question 6
Q: I want to make a picture of what might be a missing part of your agenda of addressing these issues. So in the last six… well, I guess nine months, we’ve had thinking reasoning models. And the way they are trained is through reinforcement learning with a reward function that is largely—not every company has published what they’re doing, but as far as I understand, it’s largely based on correctness and incorrectness. And there’s a danger that takes us back where basically we were afraid, the AI safety community, and more broadly, you were afraid of a literal genie style AI system that understands a single goal, ignores everything else while pursuing that goal of wreaking havoc, taking power.
But then to pleasant surprise, LLMs actually had a lot of common sense. If you asked it to do something and gave it just like a binary goal, it’s not going to destroy things. It has common sense. It understands that there’s actually multiple objectives that you didn’t say.
But in this training for thinking and reasoning, we’re using these binary objectives, and there seems to be, at least, limited evidence that does push them somewhat backwards towards being single-goal-oriented agents. Like the paper, I think, you alluded to where thinking models are more likely to cheat.
And when I hear the AI safety community speak about what should be done and including in your talk, there isn’t discussion of how to get better reward functions. The scalable oversight thing is close, but that’s really focused on things humans can’t detect well. But there’s still this really unsolved problem of just how do we craft these reward functions that track these multiple objectives that we want in a way that really respects our interests. But does that seem like that should be part of this agenda?
A: I think it does, but I guess the way I would bucket that is under step one [“Instruction-following on safe inputs”].
Q: Yeah, I think that could be one or three.
A: Yeah. I mean, step one and step three are closely connected because you ultimately you care about step three. But I think here if we’re talking about something like, okay, now we’re training these AI systems just on you’re having them do math and you’re just giving them, was the math correct or something? And maybe that is eliminating these sort of softer, commonsensical skills they’re getting from more forms of RLHF or something like that. I guess I would see that as, in some sense, yes, you’re right, it could be this or it could be step three, because you could be like, well, that was fine behavior on this particular thing, but then it generalizes poorly to maybe some form of reward hacking.
So it’s a question of is the problem you’re concerned about, say, you’re getting some more single-mindedness, some less commonsensical thing, is that occurring on the training input, or is it only in generalization?
But regardless, I agree that that’s part of it, and to some extent why I’m saying this instruction-following property is the rich commonsensical instruction following that has given people comfort with respect to LLMs. We really want AIs that do that, that aren’t literalistic genies or whatever, that have this rich nuanced understanding of what it is to follow instructions in the way we intend. And so you need to craft an evaluation signal that successfully tracks that property itself.
Question 7
Q: Yeah. So you were discussing agentic AI earlier mostly in negative light, it sounded like. You sounded concerned about the progression of agentic AI and the potential for that to not be safe. I’m interested if you’ve considered the potential safety-related usefulness of agentic AI, particularly, I would say that I believe that agentic AI provides one of the most intuitive ways that I can think of of a straightforward path to alignment actually, where you could just consider the way that humans become aligned.
So we start out, thankfully, as weak, little, tiny creatures and completely unaligned, it seems, and it’s a good thing that they’re tiny at that moment because if they had the power of a full adult, that would be really scary for a toddler having a tantrum or something and have the full power of an adult, people could get hurt.
I guess the analogy to AI would be during training, during the process of upscaling it from a really not very capable system to a highly capable, maybe, superhuman system, you could give it agentic experience that allows you to, number one, give it negative feedback when it does bad things like training a child to be good, but also to… And this gets back to your point about Bob won’t shoot me. Why do we know Bob won’t shoot me? Because I know Bob. But also, I think, an important other thing of that is that Bob will be arrested if he shoots you, and Bob doesn’t want to be arrested.
So I think another part that’s really important for agentic AI is that you have the potential to give it the experience necessary to know that there is a capable and strong enough of a system that it lives within, that if it does a bad thing, not good things will happen to it. So yeah, I’m interested to hear what you think about the utility of agentic AI systems and multi-agent systems related to AI safety.
A: So I think I alluded to this other work I have, which is also in the series that I mentioned about using AI systems to help with safety. So I have a piece called AI for AI Safety, another piece called Can We Safely Automate AI Alignment Research? And both of those are devoted to something quite nearby to what you’re talking about, which is, how do we use AI labor, including potentially agentic AI labor because many of these tasks are intuitively implicating of agency, or at least better, or it seems more easily done with agentic systems.
How do we use AI labor to help with this problem in a zillion ways? So that includes security, that includes helping with alignment research, that includes building a more robust civilizational infrastructure in general. And so basically, the answer is yes, I think using AI labor is a crucial component of this.
Now obviously, but there is this dynamic where it’s like the whole thing was maybe you didn’t trust the AIs. And so if you’re trying to use AI labor that you don’t trust to help you trust AIs, that’s at least a dance, and it’s a delicate dance, and it’s something I’m very interested in.
I also want to separate the specific thing you mentioned though, which is around punishment and deterrence as a mechanism of control. And I actually think we should be quite wary of that as a particular strategy. There’s more to say about that, but I think for both ethical and pragmatic reasons, I think it would be better, in my opinion, to focus on ways in which we can positively incentivize AI systems and also just make their motivations in the first place such that they don’t need deterrence. But it is true that that has been a part of how our own civilizational ethos, that infrastructure functions. And so yeah, it’s salient for that reason.
Question 8
Q: I just had a quick question on the slide where you first said, here’s the four things, and if we did these, that would be sufficient to solve the problem. Maybe I didn’t read this right, but I was thinking, I wonder if there’s some things outside of that that aren’t covered by these. What if you observe everything in the way here and make sure it’s okay, but there’s just a small probability that there’s some randomness in the behavior or something like that? So everything you observed, it’s okay, but then, actually, what matters is that there’s a low probability that X, Y, Z will lead to Skynet happening.
A: Yeah, I guess I would probably put that under step 3, which is sort of like you got to get all… That would be like if there’s some low probability thing where it looks good on the safe inputs but goes badly here, I would probably put that under step 3. It could be that the reason it looks good on the safe inputs was just the low probability thing hadn’t cropped up yet, even on the safe guys.
Q: That’s all right, but then there’s low probability things like all aspects of all grids in North America go down power-wise, and that takes out, actually, all of these modules that control these things. And then under those circumstances—or about the probability of a bad human actor putting malicious code in there…
A: Yeah, I mean, I don’t want to get too into this covers literally everything that would fall under the thing. And so it’s possible we could identify scenarios like that. I think this, at least in my head, if you did all these four steps, you’d be really cooking with gas, I think you’d be really in a good position. And there are other problems that I might just want to bucket separately, like humans intentionally messing with AI system, but I’m not attached to this being really exhaustive.
Okay. Thank you all for coming. Really appreciate the questions and the attention, and I wish this overall initiative good luck.
Further reading
A four-part picture.
Introduction to an essay series about paths to safe, useful superintelligence.
Building a second advanced species is playing with fire.