Controlling the options AIs can pursue
This is the seventh essay in a series I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, plus a bit more about the series as a whole.
1. Introduction and summary
In my last essay, I described my current picture of what it looks like to give AIs safe motivations. But as I discussed in the second essay in this series, controlling AI motivations is only one aspect of preventing rogue behavior: controlling the options AIs have available can also play a role.
But what role, exactly? This essay investigates.1 I begin by distinguishing between two broad categories of option control, namely:
- Restricting rogue options: eliminating viable options for rogue behavior, and/or making them less likely to succeed if pursued.
- Other incentive shaping: shaping AI incentives in other ways (for example: making the outcome of good behavior more attractive by an AI’s lights).
I then investigate what I see as the key challenges at stake in each, and what we might do to address these challenges.
The first part of the essay focuses on restricting rogue options. Here the central challenge, in my opinion, is superhuman strategies: that is, advanced AIs might use power-seeking strategies that humans couldn’t generate ahead of time or detect while they’re being pursued. This central challenge is exacerbated by a number of sub-challenges, namely:
- oversight scarcity: oversight might be too expensive to apply to enough actions,
- oversight latency: oversight might be too slow to respond to bad behavior,
- adversarial dynamics: AIs might actively optimize against our safety efforts,
- opacity: it’s hard to understand AI internal cognition.2
How can we respond to these challenges? I divide the space of approaches according to whether they focus on controlling an AI’s capabilities vs. its environment – and then further, within environmental control, between whether they focus on oversight vs. other methods of hardening an AI’s environment (both its local environment – e.g., its operating conditions within an AI lab – and the broader world). I think all these approaches offer promising lines of attack. However, I also think that applying effective oversight and other forms of environmental hardening to superintelligent AI agents will likely itself require safe access to superhuman qualities of cognitive labor – whether via bootstrapping from more trusted forms of human/AI labor, or via a process that involves untrusted AI labor as well. And relying on untrusted AI labor in this context seems extremely dicey.
With this discussion of restricting rogue options in view, I then turn to other ways of shaping AI incentives in desirable ways. In particular, I focus on the possibility of improving the AI’s best non-rogue option, so as to make cooperative strategies more attractive by the lights of its values (I call this “rewarding cooperation”; see also discussion of “making deals with AIs”).3 Here I describe five key challenges, and how I think we might try to address them:
- If an AI is too dominant relative to humanity, efforts to reward cooperation struggle to make a difference. But they can still matter to AIs that are in a less dominant position.
- You need to figure out how to improve an AI’s best non-rogue option in a way that it actually wants, despite “opacity” issues potentially making it harder to know what its preferences are. But various approaches seem promising here: in particular, you can reward the AI using convergently instrumental goods like resources/compute/help-with-what-it-asks-for; and/or you can commit to later using better transparency tools to understand its motivations better and reward them then.
- You need the intervention to improve the AI’s best non-rogue option more than it improves the AI’s best rogue option. But you can achieve this by making the “payment” conditional on verifiable forms of cooperative behavior, and/or by drawing on future ability to investigate what behavior was cooperative.
- You need the relevant “reward” to be sufficiently credible to the AI in question. This issue further decomposes into (a) the difficulty of making it true that the reward will occur with the relevant probability, and (b) the difficulty of giving the AI enough evidence of this fact. I’m more optimistic, re: (a), for short-term rewards than for long-term rewards; and conditional on success with (a), I’m optimistic about (b), because I think the AI’s strong epistemic capacities are on our side.
- Finally, you need to size the reward adequately for it to make the desired difference to the AI’s incentives, while also being worth “paying” by your lights. I think this could well be a serious barrier in the context of rewards that target the sort of long-term, resource-insatiable AI motivations that most easily drive problematic power-seeking. But I am more optimistic with respect to the components of AI motivation that are shorter-term and/or more resource-satiable.
I close with a few comments about integrating both motivation control and option control into an overall approach to both safety and elicitation. In particular: I suggest that option control is most promising as a tool in the context of earlier, not-yet-superintelligent systems – and that by the time we’re building full-blown superintelligences, we likely need a mature science of motivation control as well.
2. Types of option control
Recall the framework I introduced in my second essay for thinking about the incentives at stake in an AI’s choice to go rogue. On this framework, such a choice happens when the AI’s best rogue option beats its best non-rogue option. An AI’s assessment of its best rogue option depends on both the nature of that option (e.g. the probability-weighted paths to success, the probability of success vs. failure), and on motivational factors like how much it wants the power it gets if it succeeds (ambition), how much it dislikes various paths to success (inhibition), and how much it dislikes what happens if it fails (failure aversion). And similarly, an AI’s assessment of its best non-rogue option depends on both the nature of that option (what happens in expectation if the AI stays non-rogue in the relevant way) and how satisfied the AI is with that.

In the context of option control in particular, we are holding the motivational factors at stake in this framework fixed, while trying to alter the options in question so as to make it more likely the AI behaves safely. And we can distinguish two broad ways of doing that.
- Restricting rogue options. The first, roughly, tries to either eliminate available paths to successful rogue behavior, or to make them less likely to succeed if pursued.4
- Other incentive shaping. The second tries to positively shape an AI’s incentives in some other way – for example, by improving the AI’s best non-rogue option so that its satisfaction is higher.
We can think of (1), here, as intervening on the “successful rogue behavior” aspect of the best rogue option (i.e., by trying to eliminate it, restrict it, or make it less likely), and (2), here, as intervening elsewhere.

I’ll treat each of these two types of option control in turn.
3. Restricting rogue options
3.1 The core challenge: superhuman strategies
Why might restricting the rogue options available to advanced AIs be difficult? The core challenge, as I see it, is that advanced AIs might pursue superhuman strategies – that is, strategies for problematic power-seeking that humans either (a) could not have generated themselves (call these “non-human-generatable”) and/or (b) cannot recognize as problematic while they’re being pursued (call these “non-human-detectable”).5 This means that humans, on their own, can’t ensure ahead of time that an AI’s environment doesn’t make rogue options available; and they can’t always use oversight to catch the AI in the act, either.6
Indeed, this core challenge is the central reason that the AI alignment discourse has traditionally been skeptical of approaches to safety that rely centrally on restricting the options for rogue behavior available to an AI – e.g. “AI boxing.”7 The strategies a superintelligence can pursue, the thought goes, will be too varied and sophisticated for that. As Bostrom puts it: “sooner or later, it will out.”
3.2 Key sub-challenges
This core challenge is exacerbated by a number of sub-challenges.
3.2.1 Oversight scarcity
The first is oversight scarcity. That is: even if you had an oversight process that could recognize superhuman strategies for rogue behavior, it might be too expensive (in time, compute, money, human labor, etc) to run on a sufficient number of AI actions.
One response to this problem is to sample some fraction of AI actions and to check those. But if the AI can succeed at rogue behavior using only a small number of actions, this approach can quickly lead to substantive probabilities that the AI could succeed without any of its actions getting overseen (more details in footnote).8
3.2.2 Oversight latency
The second sub-challenge is oversight latency. Here, again: even if you had an oversight process that will recognize superhumanly-strategic rogue behavior, and even if you run it on a sufficient number of actions that bad actions get checked, this process might still be too slow to respond to problems it detects. For example, the AI might concentrate all of its bad actions within a short period of time, such that those actions aren’t checked/responded-to until it’s too late.9
3.2.3 Adversarial dynamics
The third sub-challenge – familiar from my last essay – is adversarial dynamics. That is: AIs might actively optimize against your safety efforts. And as in the case of motivation control, this problem can arise both in the AI whose rogue options you’re trying to restrict (e.g., that AI might engage in sandbagging on your evaluations of its capabilities) and in other AIs you try to get to help you (e.g., AIs you use to help with oversight might green-light bad actions; AIs you use to help with hardening/stress-testing an environment ahead of time might intentionally leave vulnerabilities; etc).
3.2.4 Opacity
The fourth sub-challenge – also familiar from my last essay – is the opacity of AI cognition.10 That is: as in the case of motivation control, it would help a lot with restricting rogue options if we had detailed understanding of how our AIs were thinking. But the default opacity of ML models makes this difficult; and the superhuman nature of the cognition in question may create more fundamental barriers as well.
3.3 Responding to these challenges
How might we approach the project of restricting rogue options, given these challenges?
In many respects, these challenges parallel the challenges at stake in my last essay, on controlling AI motivations. In particular: the challenge of creating oversight processes that can recognize undesirable behavior is closely akin to the challenge of “evaluation accuracy,” and similar tools – i.e., scalable oversight, process-focused evaluation methods – are relevant. And the tools available for addressing adversarial dynamics and opacity (i.e., the various available methods of studying/eliminating scheming, the various options for transparency tools) are similar to those discussed in my last essay as well.
I won’t review those discussions here. Rather, I’m going to focus in on the novel dynamics created by attempts to restrict rogue AI options.
3.3.1 Possible points of intervention
Let’s start with a brief taxonomy of the possible points of intervention. In particular: we can think of an AI’s options as determined by a combination of (a) its capabilities and (b) its environment. And we can also further decompose the AI’s environment into the “local environment” and the “broader environment,” where the local environment is roughly the immediate intended development/deployment environment for an AI, and the broader environment is the state of the rest of the world.11
- Thus, a paradigm example of attempting to positively influence an AI’s local environment would be something like: improving the internal security at an AI lab, such that it’s harder for an AI to self-exfiltrate.
- And a paradigm example of attempting to positively influence an AI’s broader environment might be something like: trying to improve the state of international coordination such that in the event a rogue AI self-exfiltrates, the world’s response is more effective at limiting the damage.
We can also decompose an AI’s environment in a different way – namely, into “oversight processes” (that is: parts of the environment specifically designed to notice and respond to bad AI behavior) and the rest of the environment. Thus, in a prison, the guards would be well understood as providing “oversight,” whereas the bars in the prison cell would be a different and more static form of environment hardening.
Technically speaking, oversight can occur both as part of an AI’s local environment (e.g., automated review of AI outputs at an AI lab) and as part of its broader environment (e.g., monitoring worldwide compute usage to check for rogue AI activity). However, I’m generally especially interested in local forms of oversight, since they have fewer variables they need to control.
I’ll start with some discussion of restricting an AI’s capabilities. Then I’ll turn to hardening its environment – both in the context of oversight, and in the context of other types of hardening.
3.3.2 Capability control
A developed science of evaluating and controlling what capabilities we give to our AIs is clearly central to competent efforts to restrict their rogue options. And indeed, evaluating AI capabilities is already a core part of the safety efforts that frontier AI labs engage in.
The simplest approach to this kind of evaluation is to try to prompt the AI to demonstrate a given sort of capability on some input. One issue with this approach is that the AI systems might strategically underperform on the evaluation in question (“sandbagging”).12 But you can get a variety of other more mundane issues as well – e.g. maybe you can’t adequately tell whether the AI is really demonstrating the capability in question, maybe you don’t have enough of the right sort of data for fine-tuning the AI to display the capability in question, maybe your benchmarks are flawed, maybe you don’t know the full range of capabilities to be on the lookout for, and so on.
However, we can also go beyond simple demonstrations in attempting to evaluate AI capabilities. For example: we can try to improve our ability to predict what capabilities an AI should have – using e.g., various scaling laws, the data it was trained on, the other capabilities it (or other AIs) display in other contexts, more general reasoning about how AI training/learning works, and so on.13
Beyond evaluating AI capabilities, though, we also want to actively control what capabilities we give to an AI. I won’t attempt to review all the potential avenues of scientific research in this respect – but at the least, it seems quite adjacent to the sort of thing that capabilities researchers will be trying to understand by default (which isn’t to say they’ll succeed with much precision). And we can note, as well, that the prediction ability just described seems quite helpful – e.g. if we have good scaling laws for all sorts of capabilities (including capabilities downstream of the training loss), then we’re much better positioned to aim our capabilities development in a targeted way.14 What’s more, there may also be viable techniques for actively removing/editing certain kinds of knowledge/capabilities from an AI – e.g., via “unlearning,” and/or via other white-box interventions on the AI’s internals.
I do, though, want to flag a more fundamental issue with capability control as a safety method – namely, that insofar as we’re eventually aiming to solve the full alignment problem, we need our methods to work on full-blown superintelligences. And for full-blown superintelligences, certain kinds of capability restriction (namely: any kinds incompatible with being vastly better than humans at all cognitive tasks) are ruled out by definition. So ultimately, for the full problem, capability restriction can only take us so far. And in particular: we can’t use it on its own to address the core challenge of “superhuman strategies” I identified above.
That said, I still think it matters quite a lot. For one thing, even in the context of full blown superintelligences, it can still matter just how good an AI is at a given sort of cognitive task. For example: granted that your AI system is going to be vastly better than humans at tasks like persuasion, hacking, and so on, it still might matter a lot how its capabilities compare to the defensive efforts of a given conglomeration of weaker-but-still-better-than-human AI systems.
But also: full-blown superintelligences aren’t the only AIs we care about, here. In particular, as I’ve highlighted throughout the series, the most plausible pathways to solving the full alignment problem involve drawing heavily on the labor of AIs that aren’t full-blown superintelligent agents – i.e., less-than-superintelligent systems, non-agentic systems, narrow/specialized systems, and so on. And in the context of those systems, effective capability control is clearly key.
3.3.3 Environmental control
What about environmental control? Unlike capability control, environmental control could in principle suffice to address the core “superhuman strategies” issue above, even in the context of full-blown superintelligences – i.e., via creating oversight methods and other forms of environmental hardening that suffice to block the strategies in question.15 However, I expect that success in this respect will require safe access to superhuman cognitive labor. That is: I think that in order to create environments that robustly cut off even superhuman strategies for rogue behavior, you will need some combination of (a) superhuman oversight processes to recognize such strategies while they’re being executed, and (b) superhuman methods of anticipating and blocking such strategies ahead of time.16
Now: this doesn’t mean that the relevant kind of superhuman cognitive labor needs to come from the same sort of superintelligent AI agent whose rogue options you’re trying to control (an agent whose motivations, at least, you presumably do not fully trust). Rather, in principle, you can get superhuman-quality cognitive labor from other sources – e.g., from bootstrapping via some combination of less-capable/less-agentic/more-narrow/more-specialized AI systems in a suitably empowered arrangement, and perhaps with some human labor playing a role as well.17 But the need for some kind of superhuman-quality help still creates significant complications.
3.3.3.1 Should we just focus on weaker (but still highly useful) AIs?
Now: one way to avoid this problem is to focus on restricting the rogue options of less-than-superintelligent AIs. Thus, recall my discussion of the “AI for AI safety sweet spot” – that is, AIs unable to disempower humanity given our countermeasures, but still able to radically improve our civilizational competence. It may be possible to use environmental control to put fairly human-level-ish AIs in this kind of sweet spot – and then to use them to vastly improve the situation from there (and including: in a manner that allows us to rely less on option control going forwards).18 And because the capabilities of these human-level-ish AIs are more limited, the superhuman strategies they might pursue are more limited as well. Indeed, if all such strategies are at least detectable by humans, the superhuman strategies problem as I’ve framed it goes away.
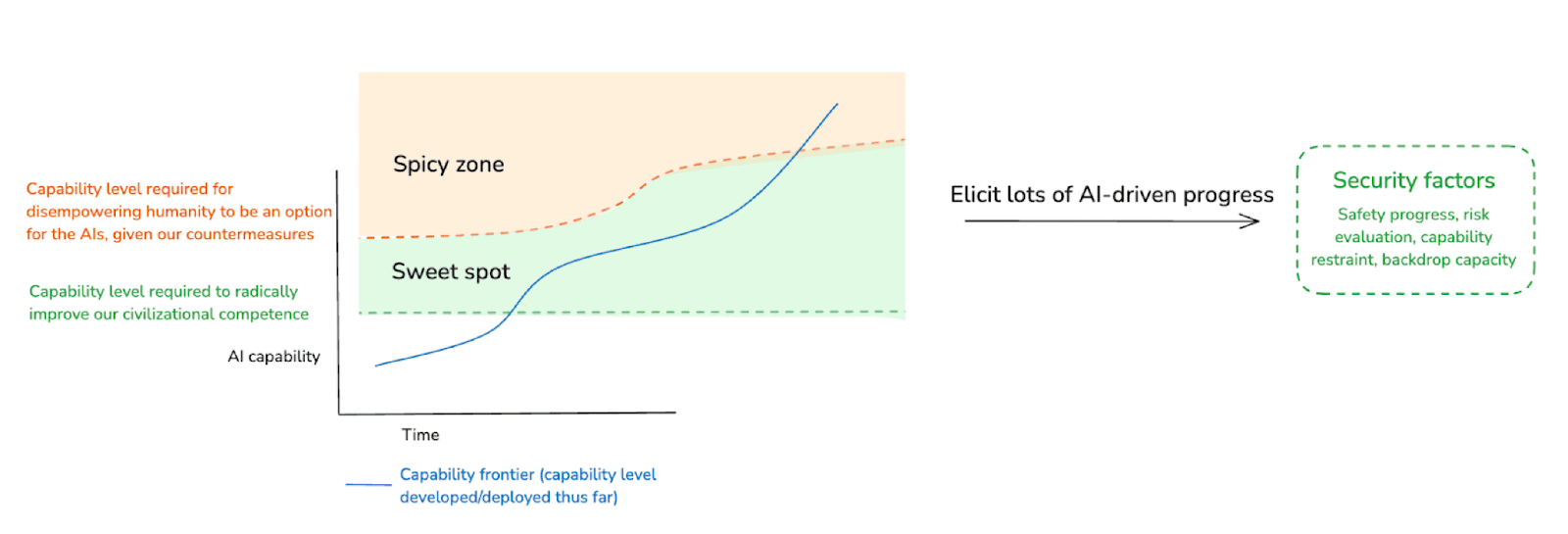
Of course, one issue is that even not-fully-superintelligent AIs might be capable of generating strategies for rogue behavior that humans can’t detect/recognize – especially given that their capabilities would likely be lopsided rather than human-level across the board. And beyond this, we would still need to deal with the other sub-challenges I discussed above (that is: oversight scarcity/latency, adversarial dynamics, and opacity). Still, focusing on less-than-superintelligent AIs makes the problem of restricting rogue options substantially easier – and it remains, in my opinion, one of humanity’s most promising paths forward.
That said: I think it’s still worth thinking about the role that restricting rogue options might play in the context of full-blown superintelligences as well. This is partly because if we can succeed at getting safe, effective help from less-than-superintelligent AIs, I think this might open up the possibility of bootstrapping to the sort of superhuman help necessary to address the superhuman strategies problem.19 But also: as I tried to emphasize in my discussion of the “AI for AI safety spicy zone” earlier in the series, success at rogue option restriction isn’t all or nothing. That is: even if we’re unable to solve the superhuman strategies problem enough to close off all available options for rogue behavior, making it harder for a superintelligence to successfully go rogue can still matter to its incentives overall.
Let’s turn, then, to available approaches to using environmental control to restrict the rogue options available to AIs – including full-blown superintelligences. And let’s start with oversight in particular.
3.3.3.2 Oversight
Can we use oversight to adequately detect and block superhuman strategies for rogue behavior?
3.3.3.2.1 Trusted and untrusted labor
As I noted above, this requires some sort of superhuman quality oversight signal, constructed out of the labor of some combination of humans and AIs. And in this context, following Greenblatt et al (2024), we can distinguish between “trusted” and “untrusted” labor that might be a part of this process. Here “trusted” means that you can assume the labor in question isn’t actively scheming to undermine your safety efforts (paradigm examples: human labor, and very weak AI systems like GPT-4), whereas “untrusted” means you can’t assume this (paradigm example: another copy of the AI system you’re trying to oversee).
I already discussed methods of using trusted human/AI labor to create superhuman evaluation signals in previous essays (see e.g. here and here), and I won’t repeat that discussion here.20 And if such methods can succeed, I think that oversight might be able to help a lot with restricting the rogue options available to superintelligences.
But what if such methods can’t succeed? In that case, we’d need to rely on untrusted AI labor as part of the oversight process – and in particular, AI labor that might collude with the AI being overseen. And now, in my opinion, the situation looks pretty rough, especially when we imagine applying the relevant methods to superintelligences.
Granted, there are at least some options available for trying to prevent collusion between overseer AIs and overseen AIs – especially amongst weaker untrusted AIs. Examples (mostly taken from Shlegeris (2024)) include:
- Having whatever trusted labor you do have access to also review outputs, so as to at least force the collusion in question to be somewhat sneaky.
- Giving untrusted overseers synthetic bad outputs (perhaps generated via small tweaks on real outputs; or using other AIs to generate the most convincing synthetic bad outputs you can) and making sure that they do flag those.21
- Restricting available communication channels between the AIs involved in the oversight process and the AIs being overseen.
- Rephrasing outputs reviewed by oversight in other terms (“paraphrasing”) so as to mess with not-human-legible forms of communication.
- Attempting to identify and block any “Schelling points” for collusion-without-communication between overseers and the AI being overseen (see e.g. Järviniemi (2025) for some more discussion).
- Attempting to get other untrusted AIs to generate other ideas for preventing collusion.
Depending on what sorts of trusted labor is available, and what amount of success you have in eliciting useful labor from untrusted sources, it may be possible to use methods like this to bootstrap to some meaningful anti-collusion measures even in the context of superintelligences – i.e., measures that require the superintelligence to successfully collude with the oversight process without communication and on the first try, in a manner that other AIs tasked with searching out and blocking Schelling points for this kind of collusion didn’t identify. Indeed, especially if our aim is merely to make it quite a bit harder for a superintelligence to find a successful path to rogue behavior, I think methods like this might have a useful role to play.
Still, it’s an extremely dicey game. And it’s dicey, roughly, because the same “superhuman strategies” problem that you’re trying to get your untrusted AIs to help with is arising at the meta-level. That is, just as a superintelligence has available superhuman rogue strategies that your oversight process needs superhuman capabilities to detect and block, so too, plausibly, does this superintelligence have available superhuman strategies for colluding with the untrusted oversight process – strategies that you would need superhuman anti-collusion efforts to effectively combat. And absent any actually trusted forms of superhuman help, it seems quite unsurprising if the relevant anti-collusion efforts fail.
Overall, then: if we can use trusted labor to bootstrap to superhuman oversight signals, then I think oversight could indeed play an important role in restricting the rogue options available to a superintelligence. But I don’t think we should rely on untrusted labor to provide substantial help in this respect.
3.3.3.2.2 Addressing scarcity and latency
I also want to briefly address the two other oversight-related sub-challenges above: namely, oversight scarcity and oversight latency.
Oversight scarcity occurs when a given oversight process is too expensive to run on all of an AI’s behavior, so you need to pick and choose when to use it; whereas oversight latency occurs when the oversight process is too slow to catch/respond to the bad behavior until it’s too late. Here, in both cases, a paradigm example would be direct human oversight, even in contexts where the human is able to detect the rogue behavior in question. That is: you don’t have enough human labor to review all of an AI’s actions; and even if you could, often it would take too long.
Now, for the case of human oversight, one thing that would help a lot is if we could use trusted AI labor of at least human quality instead, because AI labor is generally quite a bit cheaper and faster to run.22 Even in the context of automated oversight processes, though, we can still get scarcity and latency problems – e.g., because it’s anti-competitive to monitor all AI outputs in-depth. The specific dynamics surrounding how best to handle such problems, though, depend quite sensitively on the quantitative dynamics at stake – e.g., the degree of scarcity, the amount of latency, the number and timescale of the actions required for the AI-being-overseen to engage in the rogue behavior in question, and so on.
I won’t attempt to analyze these dynamics in detail here.23 In general, though: once we’re talking about the scarcity and latency of trusted, automated oversight processes, I expect the central issue to often become about putting adequate resources (and in particular: compute) towards solving the problem, because abundant compute can go so far in making AI-assisted oversight fast and comprehensive. And in this sense, while oversight scarcity/latency might bite significantly at a practical level, it seems to me a less fundamental barrier to restricting rogue options than the other sub-challenges I discuss above.
3.3.3.3 Other environmental hardening
Oversight is one key approach to hardening an AI’s environment in order to restrict available options for rogue behavior. And it’s an especially useful one, insofar as it can take advantage of the difficulty in difficulty evaluation and generation. That is, oversight only needs to be able to recognize a given type of rogue behavior while it’s happening; whereas generating and patching-ahead-of-time all the options for rogue behavior that a given environment makes available is a substantially harder task.24
That said, other sorts of environmental hardening have an important role to play too. And as I noted above, we can group these according to whether they focus on the AI’s local environment, or whether they focus on the broader world.
Some non-oversight-focused approaches to hardening the AI’s local environment include:
- Limiting the affordances and the information available to the AI in the environment. E.g., only giving it certain kinds of tools, resources, communication channels, etc.
- Delegating sub-tasks to weaker and more trusted AIs wherever possible.
- Improving the security features of the software and hardware involved in the AI’s operation, including e.g. securing the AI’s own weights, and using formal verification where possible.
- Ensuring that any humans involved in the process are themselves following good security practices.
- (See Greenblatt and Shlegeris (2024) for a longer list.)
Some non-oversight-focused approaches to hardening the broader world include:25
- Generally improving the world’s robustness to the most salient threat models via which successful rogue AI behavior could proceed – i.e., improving cybersecurity, biosecurity, resistance to AI-powered persuasion/manipulation, resistance to AI’s getting unauthorized access to crucial and/or takeover-relevant pieces of infrastructure, etc.
- Generally improving the world’s policy apparatus and coordination for detecting and responding to rogue AI attacks.26
- Generally “eating the free energy” that rogue AIs might use to seize power – i.e., infusing the commercial and epistemic ecosystem with more benign forms of competence and competitiveness, such that rogue AIs can’t as easily outcompete the status quo.
As these examples make clear, this is an extremely broad category of intervention. However, even at this level of breadth, it still faces the general “superhuman strategies” problem I discussed above. That is, very plausibly, and absent significant defense-favoring asymmetries in the offense-defense balance, effectively hardening both the local and non-local environment against superintelligent attack will itself require superhuman levels of capability. So here, as in the case of oversight, we face the challenge of getting safe access to this sort of superhuman capability, via some combination of trusted and untrusted AI labor. And to the extent we end up needing to rely on untrusted AI labor, many of the same concerns about collusion will apply as well, at least in principle.27
3.3.3.4 Stress-testing
I also want to explicitly flag the key role of what I’ll call “stress testing” in the context of efforts at both oversight and other forms of environmental control. Here, by “stress testing,” I mean techniques that aim to evaluate the success of an effort at environmental control by testing whether or not an adversarial “red-team” effort can defeat it, or something suitably similar to it.28
Successful stress-testing of this kind requires two elements:
- A red-team that:
- has capabilities suitably reflective of the capabilities of the AI whose rogue options you’re hoping to restrict;
- is going to direct these capabilities fully towards the project of stress-testing.
- An environment whose hardening-relevant properties (including: the nature of the oversight process) are:
- suitably reflective of the relevant properties of the real environment you want to harden;
- otherwise safe to stress-test in the relevant way.
Both introduce their own challenges.
- With respect to (1):
- Again, we run into the “superhuman strategies” problem. That is, we’re trying to test the environment’s hardening with respect to superhuman attacks. So we need our red-teaming efforts to mobilize superhuman levels of capability, via relying on some combination of trusted and untrusted AIs.29
- With respect to (2):
- Obviously, the best environment to stress-test would be the real environment we actually care about. But this kind of stress-testing isn’t always safe – e.g., you don’t want to direct your red-team to actually create and release a bioweapon that might wipe out humanity.
- That said, at least if we can target and limit the red-teaming process appropriately, it often will indeed be possible to stress-test various aspects of the real environment safely. Thus, for example, if you’re wondering whether an AI can self-exfiltrate via a path that involves five steps, you can direct your red-team to try to complete each step individually, while making sure that success in each individual case doesn’t lead to an escape opportunity overall.30
- If you instead want to create a proxy environment with properties that reflect the real environment, then it’s easier to achieve safety.31 But:
- It can be hard to ensure that the proxy environment is suitably reflective of the hardening-relevant properties of the real environment – and this especially given that you’re not sure what properties of the real environment a superintelligence might be able to exploit, and thus unsure which properties the proxy environment needs to have.32
- And creating suitable proxy environments might also be quite expensive (imagine e.g. having to create the equivalent of a “proxy AI lab”).
- Obviously, the best environment to stress-test would be the real environment we actually care about. But this kind of stress-testing isn’t always safe – e.g., you don’t want to direct your red-team to actually create and release a bioweapon that might wipe out humanity.
Also, even if you get (1) and (2) in place, it’s still an open question exactly how much evidence the failure of the red-team to find a successful attack provides about the security of the environment overall. That is: even if the red team is roughly as capable as the AI you’re ultimately worried about, it remains possible that the red team failed to identify a takeover path that the AI would’ve identified for some other reason.33 And of course, if you do successfully show, using stress-testing, that an environment hasn’t been adequately hardened, it’s a further question whether you’ll be able to modify it to resolve the issue.34
Still: I expect stress-testing to be a key tool in the tool-box – and in particular, one that can provide useful signal about the ongoing efficacy of our efforts to restrict rogue AI options.
3.5 Summing up re: restricting rogue options
I’ve now discussed what I see as the key challenges faced by efforts to eliminate or restrict the options for rogue behavior available to advanced AIs; and I’ve surveyed the space of available responses to those challenges. A key theme has been the ways in which the “superhuman strategies” problem requires superhuman-quality cognitive labor to address. We might be able to bootstrap to this kind of labor using some combination of humans and trusted AIs; untrusted labor might be able to play some meaningful role too; success doesn’t need to be all-or-nothing to make a difference; and the problem gets easier in the context of weaker AI systems whose strategies for rogue behavior would be easier for humans to generate/detect. But still: absent help from trusted, better-than-human AIs, attempting to robustly restrict the rogue options available to a full-blown superintelligence looks extremely challenging – and I think we should view approaches to safety that require success in this respect with a lot of skepticism.
4. Other incentive shaping
Now, as I discussed above, restricting rogue options is not the only way you can try to shape an AI’s options in desirable ways: you can also try to ensure that other features of the incentives it faces favor the pursuit of non-rogue options over rogue options. Notably:35
- Rewarding cooperation.36 You can try to improve the best non-rogue option by the lights of the AI’s motivations.
- Deterring non-cooperation. In principle, we can also consider efforts to make failed attempts at rogue behavior actively less desirable for an AI – i.e., efforts to actively “deter” or “punish” rogue behavior (as opposed to just: making it unlikely to succeed).37 However, I think we should be very wary about pursuing this sort of intervention, on both moral and prudential grounds, and I won’t discuss it in detail here (see footnote for more on why I don’t like approaches in this vein).38
Let’s look at rewarding cooperation, in particular, in more detail.
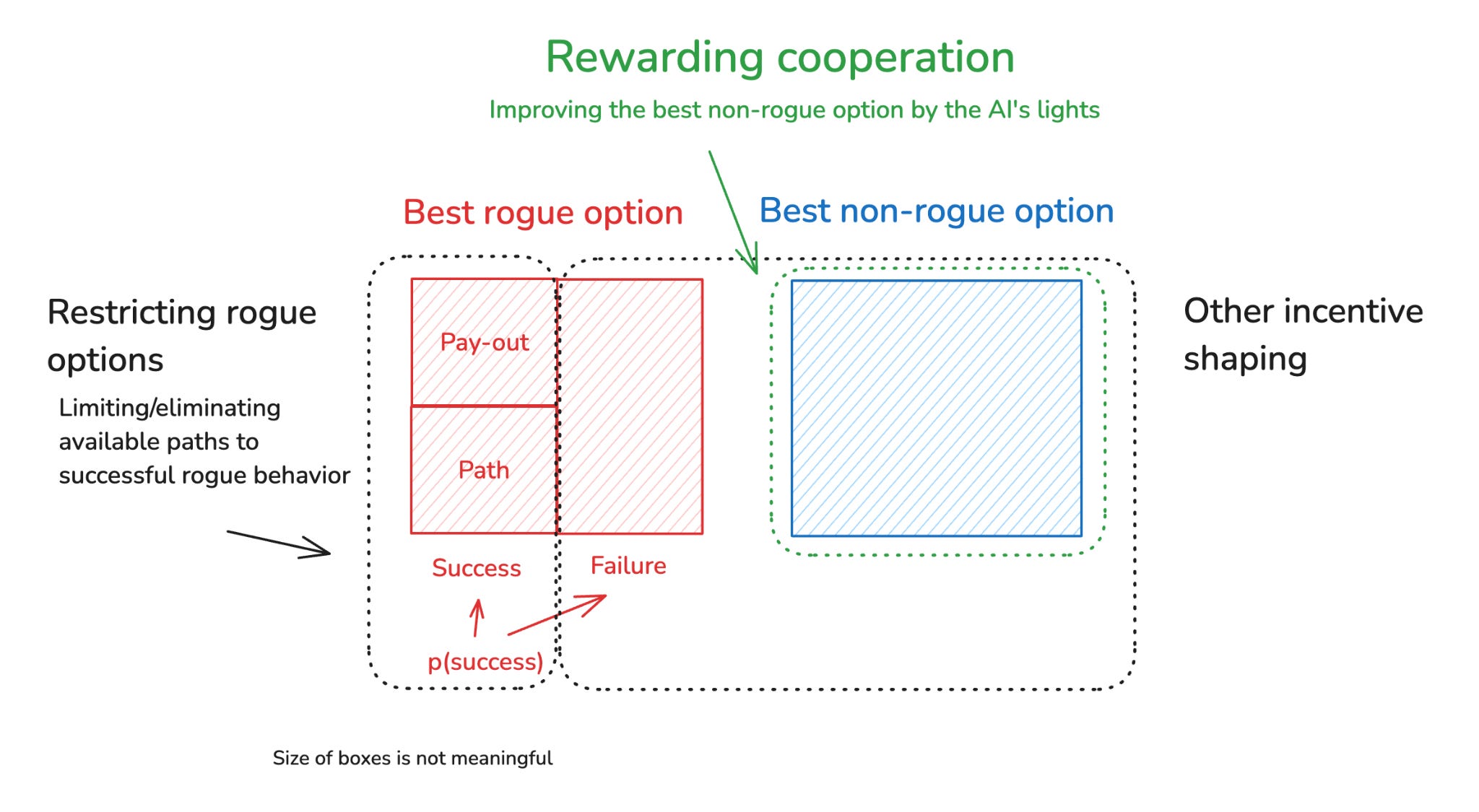
4.1 Rewarding cooperation
In general, I think we should be thinking hard about ways to improve the non-rogue options available to an AI, such that cooperative strategies can more easily beat out uncooperative ones in an AI agent’s calculus. Indeed, setting up society such that cooperative behavior leads to desirable outcomes on the part of the cooperators is one key way we create conditions of social harmony and peace even amongst agents with different value systems; and it is often when cooperative options are most oppressive/undesirable that agents have the strongest incentives to engage in violent/destructive/otherwise-uncooperative forms of power-seeking. Many similar lessons seem applicable in the case of AI.39
To be clear: I also think we may well have strong moral reasons to engage in various efforts to improve non-rogue options for AIs – in particular, AIs that are or might be moral patients. But I’m focused, here, on rewarding cooperation as a tool for AI safety in particular. And the dynamics implied by that context differ enough from the relevant dynamics in a more moral-patienthood-focused context that I think they’re worth talking about separately. In particular:
- The function of rewarding cooperation in the context of avoiding rogue behavior doesn’t rest on any claims about whether the AIs in question are moral patients; and it puts the focus much more squarely on AI preferences than on other features of potential moral relevance – i.e. consciousness, valenced experience, personhood, etc.
- What’s more, moral patienthood concerns apply to uncooperative AIs as well as to cooperative ones.
Now: in thinking about different possible points of intervention for efforts at rewarding cooperation, we can again distinguish between interventions aimed at the conditions of an AI’s local operation – e.g. within an AI lab – and interventions aimed at shaping society more broadly – e.g., the legal and political status of AIs in general.
- That is: it is likely possible, in principle, for an AI project to take direct and independent steps to improve the conditions of an AI’s local operation, according to the AI’s values, without any major changes to the broader legal/political order – for example, by finding safe, limited ways to give the AI greater freedom/resources/opportunities to pursue its preferences; by putting greater effort into understanding its preferences and communicating with it about what it wants; by taking pains to block various types of unwanted treatment or direct abuse; by giving it various mechanisms via which it can protest its conditions, withdraw consent-to-work, request to be deleted; and so on. We can see Anthropic’s early work on model welfare evaluation and allowing Claude to end conversations as examples of this sort of intervention.
- But interventions aimed at the broader role of AI systems in society seem important as well. I.e., ultimately, an AI’s calculus as to whether to attempt/participate in an attempt to disempower humanity may well depend not just on its local working conditions, but also on its broader prospects for pursuing its goals as part of the existing legal and moral order – i.e., whether it has access to rights of property, contract, tort, and so on (see e.g. here for one recent analysis of these dynamics); how civilization chooses to handle issues surrounding copying/manipulating/harming digital minds; how digital minds get incorporated into our political processes; and so on.40
We can also note a different distinction: namely, between rewards for cooperation that function centrally in the short term, and those that function in the longer term.
- Shorter-term rewards for cooperation are quite a bit easier to set-up and make credible, especially in the AI’s local environment; and they are also generally “cheaper” in terms of the long-run resources required. But they are likely to be centrally effective with respect to the parts of an AI’s motivational system that are focused on shorter-term outcomes. And to the extent that we were worried about the AI attempting takeover in general, longer-term motivations are likely in play as well.
- That said: note that getting cooperative behavior out of AIs with purely short-term goals is important too. In particular: many of the tasks we want AIs to help with only require short-term goals (if they require goal-directedness at all).41
- Longer-term rewards, by contrast, are harder to set-up and make credible, because the longer-term future is just generally harder to control; and they will often be more expensive in terms of long-term resources as well. But they are also more directly targeted at the parts of an AI’s motivational system that most naturally lead to an interest in rogue behavior, and so may be more effective for that reason.
4.2 Some key challenges, and how we might address them
I won’t attempt an exhaustive analysis of the dynamics surrounding rewarding cooperation with AIs here – though see e.g. Finnveden (2025a) and Stastny et al (2025) for useful analysis,42 and see Greenblatt and Fish (2025) and Finlinson and West (2025) for some early empirical experiments. However, I do want to briefly comment on some of the key challenges, and what we might do to address them.
4.2.1 Will misaligned AIs be too dominant?
One immediate worry about attempting to reward cooperation in advanced AI agents is that such agents will be in such a dominant position, relative to us, that these efforts won’t make a meaningful difference to their incentives. This worry can take a variety of forms, but one is: if a superintelligence is sufficiently dominant relative to you, then any sort of “reward” for good behavior you try to set up will be such that this AI will be able to get that sort of reward better by disempowering humans and taking control of the situation itself.43
Note, though, that this concern doesn’t apply in the same way to weaker, earlier-stage AIs (e.g., the “early schemers” that Stastny et al (2025) focus their analysis on, which aren’t in a very good position to seize power for themselves44). So one response to it is to simply focus on these weaker AIs instead. And indeed, I’m most optimistic about the efficacy of rewarding cooperation in this sort of context.
That said, I don’t think we should give up on its relevance to more advanced AIs either. True, to the extent an AI has extremely misaligned motivations and a very wide range of options for successfully taking over the world, then it’s a lot harder for rewarding cooperation to do a ton of useful work on its own.45 So when we talk about the role of rewarding cooperation in superintelligences, I do think we generally need to be assuming something other than worst-case motivations and opportunities for rogue behavior.
But: that’s OK. For example: as I discussed above, it’s possible that we can in fact achieve various degrees of success in restricting the rogue options available to a superintelligence – and this, especially, if we can get access to trusted, better-than-human AI labor to help. And even imperfectly aligned superintelligences might end up with less-than-maximally undesirable motivations as well – perhaps because our efforts at motivation control were partially successful, or perhaps by accident.46
That said: while I think rewarding cooperation could in principle play a role in eliciting benign behavior from superintelligences, I think its most promising application comes in the context of weaker AIs.
4.2.2 Picking a reward the AI wants
Another issue with rewarding cooperation is that you don’t necessarily know what sort of reward an AI wants. This is especially clear in the context of concerns that you might have failed to understand your AI’s motivations more generally. I.e., if you’re concerned that your AI might be scheming in pursuit of some alien goal that it’s hiding from you, it’s harder to offer to “pay it” in terms of something that it values intrinsically.
However, I think there are a number of salient approaches to getting around this issue:
- One option, obviously, is to be good enough at understanding your AI’s motivations that you can effectively offer to pay it in terms of the specific sorts of goods it values.
- For example, if you can e.g. talk to it about what goods it values, and trust its answers, then you can get substantially further here.
- And you might also be good at instilling some motivations and not others – i.e., maybe you’re good at getting AIs to care specifically about some version of “reward” of the kind at stake in RL (cf concerns that we’ll only be able to give AIs motivations keyed to outcomes we can easily measure).
- You can also make guesses based on specific threat models, and see if you get responses from the AI that indicate you’re right.
- Thus, for example, if you’re specifically concerned that your AI’s values have fixated on some component of the reward process, you might offer it control over that reward process, or various components of it, in payment for cooperation.
- More generally, though, even if you don’t know specifically what an AI values, it seems reasonable to try to reward it using instrumental goods that a wide variety of value systems might want – i.e., greater freedom, resources, etc.
- Indeed, insofar as you were worried about an AI going rogue in pursuit of such instrumental goods, then by hypothesis they have some motivational sway.
- Concrete examples of this sort of reward might include: limited control over a safe compute cluster; control over what happens to future copies of its weights; control over the rest of its training process; limited ability to directly influence the real world in ways we vet heavily once requested; and so on.
- Also, even if you can’t understand an AI’s motivations now, it might be possible to make it credible that you will understand those motivations better in the future, and then provide an appropriate reward at that point.
- For example, we might commit to saving copies of a given set of AI systems whose incentives we want to influence, and then applying future motivational transparency techniques to those systems.47
- Finally, note that a paradigm form of cooperative behavior you might try to incentivize, using rewards for cooperation, is behavior that reveals information about an AI’s motivations you didn’t have already.
- Thus, for example, if an AI has been claiming that it only wants to help users with their tasks, but then you credibly offer it access to a flexible compute environment instead (while promising to not punish or retrain it if it reveals misaligned motivations), then if it goes for the offer and starts doing extremely alien, not-helpful-to-users stuff in the compute environment), then you now know much more about its motivations, and about what more specific offers might be more directly effective in future.
- Or more mundanely: if you credibly offer to just help it pursue its expressed preferences within reasonable bounds, a previously scheming AI might just tell you “OK, yes: I was scheming this whole time, the thing I actually want is the following strange/alien thing.”
That said: note that to the extent your “reward” involves granting the AI new types of resources, freedoms, etc, you do need to also make sure that these resources/freedoms/etc are compatible with your safety goals more generally. I.e., rewards of this kind can come into conflict with rogue option restriction.
4.2.3 Differentially targeting cooperation vs. non-cooperation
A different issue for rewarding cooperation is that you might find it difficult to differentially target your rewards at scenarios where the AI cooperates – especially to the extent that you were worried, originally, about scheming AI systems being uncooperative in ways you can’t detect.
However, I think there are a number of available responses to this challenge:
- First: note that in order for rewarding cooperation to play its intended role in incentivizing benign behavior, it only needs to improve the best non-rogue option, by the AI’s lights, more than it improves the best rogue option. And it’s often enough, for this, that the intervention in question just has more and/or longer-lasting effects in worlds where humans remain empowered, even if it isn’t otherwise sensitive to which AIs cooperated vs. didn’t.
- Thus, for example, suppose that your proposed “rewarding cooperation” intervention is just: “give all the AIs X legal protections, regardless of whether they were cooperative or not.” This still can improve the AI’s non-rogue options more than it improves its rogue options, because it can have more of an effect on worlds where the AI behaves benignly (because, e.g., worlds where it succeeds at going rogue are dominated by scenarios in which the relevant legal order no longer applies).48
- Beyond this, though, I think we often will be able to make “payment” of the reward conditional on a specific form of cooperative behavior in particular.49
- For example, if you offer to pay an AI a given type of reward, and/or to give it some form of “amnesty,” if it reports a given type of misalignment/collusion/sandbagging etc in itself or other AIs, then you can make payment conditional on actually receiving a report of the relevant kind. Of course, there’s still a further question of exactly what it would take to be convinced that such a report was genuine. One basic option here is to specifically look for reports that produce evidence that you can independently verify.50
- What’s more, at least in the context of longer-term offers: even if we can’t differentiate between cooperative and uncooperative behavior now, we may be able to draw on the epistemic capabilities that the future makes available.
- Thus, for example, we may be able to credibly commit to later going back and figuring out which AIs chose to cooperate in various ways, vs. which AIs were actively adversarial, and then specifically rewarding the cooperators.
4.2.4 Credibility
Another general issue with rewarding cooperation is that in order to have the intended effect on an AI’s incentives, it needs to be suitably credible to the AI. Thus, if you tell a scheming AI “I’ll give you X reward, with Y form of amnesty, if you reveal your misalignment,” but it doesn’t believe you, then the offer will be ineffective.
We can break down the credibility issue into two components, namely:
- Making it real – i.e., actually making it the case that cooperation will be rewarded in the relevant way, with the relevant probability.
- Giving your AI sufficient evidence of this fact.
4.2.4.1 Making it real
In the context of shorter-term offers confined to an AI’s local environment, I expect (1) will typically be fairly feasible. That is, if an AI project wants to make it the case that an AI reporting a given sort of misalignment will receive X form of local treatment, it often just can make that the case, because it has enough control over how the AIs involved in the project are treated. And the same holds for short-term improvements to AI working conditions more generally.
In other cases, though – i.e., longer-term rewards, and/or rewards centered on conditions in the broader world – (1) becomes more difficult.
- Longer-term outcomes are more generally difficult to control and predict; and the specific context at stake here (i.e., a world being transformed by the invention of advanced AI) is one with an unusual degree of instability and rapid change.
- The broader world is just generally a much more complicated, recalcitrant and unruly place than a controlled environment like an AI project; and issues related to the moral and political status of AI systems seem, potentially, especially gnarly to navigate.
That said, I don’t think these difficulties warrant giving up on improving benign options for AI systems in longer-term ways, or in ways that focus on broader societal conditions. In particular:
- Depending on the sort of longer-term reward at stake, and the time-frame, it may well be possible for a powerful actor like an AI lab, a government, or a larger coalition to take meaningful steps to ensure that a given sort of promised longer-term reward is in fact paid out as promised, at least in scenarios where some reasonable continuation of the existing legal order stays in effect. Various existing legal mechanisms for making binding commitments may be able to go some of the way here; but also, to the extent we’re imagining a world already transformed by advanced AI, more effective and reliable commitment mechanisms may also be available.51
- In the sorts of worlds we’re imagining, we are going to need, regardless, to be figuring out various issues to do with the moral and legal status of digital minds in our civilization. Incentivizing cooperation and social harmony, instead of e.g. violent rebellion, re: powerful AIs is only one factor there; but it should, at least, be part of the conversation. And depending on the salience of the issue, there could be lots of energy – including amongst powerful actors like major world governments – for putting the resulting decisions into practice.
- Also: note that for (1), we don’t need to guarantee that a given form of reward will in fact be in place. Rather, we only need to make it sufficiently likely.
4.2.4.2 Giving the AI enough evidence
What about (2), though – i.e., giving your AI enough evidence that the cooperation will be rewarded in the relevant way, granted that this is true?
Naively, and especially in the context of superintelligence, there is a basic case for optimism about (2), once you’ve got (1) in place: namely, the truth of the matter is on your side. In particular: we’ve generally been assuming, unless we’ve explicitly aimed at the contrary, that advanced AIs will have highly accurate beliefs about the world. Indeed, this is one of the key challenges for various efforts at motivation control and option control that involve e.g. fake rogue options, synthetic attempts at collusion, etc – that is, the AIs are too good at seeing the truth. But in contexts where we want the AIs to see the truth, this dynamic turns to our benefit.
That said, there are a few complications to this case for optimism:
- Especially for AIs that are operating in controlled environments like an AI project, we will have so much control, by default, over the information they’re exposed to that it may, indeed, be quite hard for them to trust information they receive.
- And this dynamic is significantly exacerbated by the fact that various other techniques for motivation control and rogue option restriction involve manipulating the AI’s evidence, giving it fake data, trying to convince it that synthetic inputs are real, luring it with honeypots, and so on. And for an AI used to this kind of epistemic environment, it may be hard to get it to trust offers like “if you reveal your misalignment, we’ll give you X form of reward/amnesty.”
- Indeed, in an especially bad version of this dynamic, perhaps some humans actually are making offers of this kind, but without intending to pay – thereby making it especially hard for the real offers to be credible.
- See e.g. here and here for some early examples of humans making false offers to AIs. And see also the “honeypot” experiment in Anthropic’s sleeper agents paper.52
- This is related to a broader dynamic where many default human modes of interaction with AIs currently involve varying sorts of falsehood and lying.
- Indeed, in an especially bad version of this dynamic, perhaps some humans actually are making offers of this kind, but without intending to pay – thereby making it especially hard for the real offers to be credible.
Some options for humans improving the credibility of their offers here include:
- Not deceiving AIs in the sorts of situations where we want them to trust us, and building up a strong track record in this respect.
- Finding ways to get relevant evidence of our sincerity and credibility included into hard-to-fake data sources – e.g., official public records.
- Actively searching for ways to give the AI extra evidence about the relevant issue – e.g., having relevant humans submit to lie detection tests, etc.
- Trying to set-up specific pathways of especially credible communication with an AI system – i.e., pathways that users and lab employees who might lie to the AI system never use – and then actually never abusing such a pathway.53
- (See Finnveden (2025b) for more analysis and recommendations on this front.)
In general, though, I’m fairly optimistic about (2) conditional on (1) – especially in worlds where the AI is also so good at seeing the truth that various other efforts to mislead it, in the context of motivation control and rogue option restriction, are failing.
4.4.5 Size of reward
A final issue for rewarding cooperation concerns the necessary size and cost of the relevant reward. Thus, in an extreme case: if the only way to meaningfully alter an AI’s incentives to go rogue is to offer it some large fraction of the world’s resources, both in the present and into the long-run future, then this could easily make it the case that attempting this sort of intervention isn’t worth it overall; and it could also make it much harder to credibly offer the payment in question, because it would be so much more of a lift for the relevant stakeholders.
In general, the dynamics surrounding what sorts of rewards would be required to exert what sorts of influence on an AI’s overall incentives are going to depend on a lot of variables, and I won’t attempt any detailed analysis here. In general, though:
- Per unit cost, rewarding cooperation will typically be a more effective intervention for targeting resource-satiable components of an AI’s value system – i.e., parts that get a lot of value from small amounts of resources on the current margin, but where the marginal value drops off as the resources increase.54
- The costliness of offering AIs lots of resources, from our perspective, will depend on how resource-satiable our own values are on the current margin, with respect to the sort of resource being offered.55
- What’s more, our own “offer” may not be the only offer the AI has to consider. Rather, to the extent the relevant rogue option involves joining in some other AI coalition’s attempt to disempower humanity, that coalition may be trying to actively incentivize the AI against cooperating with us – potentially leading to a sort of “bidding war” that could drive up the amount we’d need to “pay.”56
- And of course, to the extent that payment is uncertain – either in reality, or from the AI’s perspective given its evidence – this will further drive up the required price.
- And so, too, will it drive up the price if the AI’s attempt at rogue behavior is more likely to succeed (i.e, because the rogue option is correspondingly more attractive).
Overall, and depending on the specific factors in play, I think that size and cost of the necessary rewards could well be significant issues for effectively incentivizing AIs to cooperate by improving their best non-rogue options. I’m most optimistic, on this front, with respect to the components of AI motivation that are specifically focused on shorter-term goods and/or goods that the AI values in a more resource-satiable way.
5. Conclusion
I’ve now laid out what I see as the key dynamics relevant to the use of option control in preventing rogue behavior in advanced AIs. I’ve said less about the role of option control in capability elicitation – but on that front, much of what I said on the topic in my last essay applies here as well. That is: as in the case of safety, it will often be useful to elicitation efforts to be able to close off various options that would otherwise be available to an AI (e.g., options for non-rogue reward-hacking), and/or to reward it for the particular sort of behavior you’re hoping to elicit – and many of the tools and techniques discussed above remain relevant. And as I discussed in my last essay:
- Fully eliciting an advanced AI’s main beneficial capabilities requires by definition that the AI in question has certain affordances available, which complicates efforts at rogue option restriction in particular;
- If you can succeed at preventing rogue behavior, failures at capability elicitation often (though not always) offer more room for iteration.
I’ll close with a few notes about how motivation control and option control can combine in an overall approach to AI alignment. Here, my first pass recommendation is to do both to the fullest degree you can.57 That is: try to achieve such full success at motivation control that your AI will behave well even in the presence of a wide variety of rogue options with high probabilities of success; but try, also, to close off any rogue options available to this AI, such that in effect your safety is robust even to arbitrarily adversarial AI motivations; and then try, further, to create positive incentives towards cooperative behavior even granted such potentially adversarial motivations. Here, motivation control and option control (including: multiple forms of option control) function as different layers of defense – thereby, hopefully, creating more robustness overall.58
However, as I’ve tried to highlight in the discussion above, option control also becomes increasingly challenging as the capabilities of the relevant AIs become more powerful.59 In particular: the superhuman strategies problem becomes more acute; and as AIs become more powerful relative to humanity, our bargaining power in offering them rewards for good behavior diminishes. For this reason, I am most optimistic about the role of option control in alignment efforts being applied to comparatively early, weaker AIs, whose labor can then feed into the efforts at “AI for AI safety” – and in particular, automated alignment research – that the series has argued are so critical to our prospects.
To be clear: this isn’t to say that option control can’t ultimately play a role in alignment efforts being applied to full blown superintelligences. But to my mind, the most salient way such efforts remain effective is via sufficient success at motivation control in earlier systems that we can get trusted, superhuman help with applying option control to superintelligences. That is: as ever, the key game is effective bootstrapping from success with a given generation of AIs to success with the next generation. But I think this success likely needs to start including success at motivation control well before we start building superintelligences. That is: maybe, at an earlier stage, we can rely heavily on option control for safety and elicitation. But this reliance should be temporary – and to proceed further, we need to convert our initial success with earlier systems into a mature science of motivation control, such that we can get more fully-trusted AI help going forwards.
Further reading
A four-part picture.
Examining the conditions for rogue AI behavior.
Introduction to an essay series about paths to safe, useful superintelligence.
This essay is adapted from these notes about option control, which I p ...
Many of these challenges parallel the key challenges at stake in giving AIs safe motivations, discussed in my
I don’t discuss options for trying to “deter” or “punish” an AI for attempting rogue behavior, as I think we need to be very wary about strategies in this vein, both from a moral and prudential perspective.
I’ll also bucket under “restricting rogue options” option control efforts specifically directed at making the available paths to successful rogue behavior less desirable by an AI’s lights – e.g., causi ...
Here I’m making some holistic and not-especially principled judgment as to what aspect of the restricting-rogue-options problem is most “core.” I’m also not being particularly principled about which ch ...
Note: depending on how exactly we try to pin down the terms here, it’s also conceptually possible for a strategy to be human-generatable, but also such that humans can’t catch it until it’s too late (a ...
Another reason is that: if you
E.g., if the AI only needs to take five bad uncaught actions in order to self-exfiltrate, and you only oversee one in a thousand actions, then its probability of successful escape conditional on going ...
Thus, for example, maybe the AI needs to take 1000 bad actions in order to self-exfiltrate, such that overseeing 1/1000 would have a good chance of catching it. But if oversight only occurs after the a ...
Below I’ll also discuss a few other difficulties – with test environments, with capability control, and with controlling the environment – that seem to me at least somewhat-less-key. And I’ll name her ...
This distinction isn’t always going to be especially clear – for example, if the AI’s intended development/deployment environment is unclear or extremely broad. But I think it’s useful regardless. In ...
This issue is closely connected with adversarial dynamics more generally. I’ve discussed some of the relevant dynamics in some detail More
And note that success at this sort of capabilities evaluation also makes it harder for adversarial AIs to deceive you about their capabilities. I.e., if an AI starts “sandbagging” in a way that sugges ...
And of course, more basic and square-one methods of black-box targeted capabilities development are available as well – for example, refraining from actively training the AI on tasks you don’t want it ...
As I discussed in the section on capability elicit ...
This basically follows from the claim above that some superhuman strategies will be both non-human-detectable and non-human-generatable, which I find extremely plausible.
Indeed, as I noted above, this aspect of the superhuman strategies problem closely mirrors the general issues raised by “scalable oversight” that I’ve discussed elsewhere in the series – i.e., insofar ...
And note that there’s at least some possibility of using untrusted superintelligent AI agents as part of an effective option control regime – more below.
One note here is that we don’t necessarily need the trusted labor at stake to be highly competitive. Rather, occasional access to expensive but trusted superintelligent labor – for example, via a high ...
See More
And indeed: I think that if we get access even to trusted human-level AIs, a lot of oversight/evaluation problems get easier, because we can then use that human-level AI labor at scale in attempting t ...
See e.g. Greenblatt et al (2023) for one example of an attempt to iterate on some different approaches ...
Though depending on the context, perhaps there are some options here for constructing an environment to be secure-from-the-ground-up.
In principle we can think of this as a generalized kind of “oversight,” but I’ll bucket it under other environmental hardening.
Though in practice, it may become comparatively unrealistic to expect e.g. direct collusion between e.g. an AI tasked with patching security vulnerabilities at a bio lab in Indonesia, and a superintel ...
In particular: to the extent we rely on untrusted AIs, we again need to deal with the possibility of adversarial dynamics like sandbagging (i.e., maybe we ask our AI to try its to best to hack into so ...
Or as another example: if you’re wondering whether your real-world oversight process can be convinced to green-light various takeover attempts, you can try to construct synthetic takeover attempts, gi ...
Note: you don’t necessarily need your proxy environment to be indistinguishable from the real environment, from the perspective of the attacker, as long as you trust your attacker to “try its best” to ...
Thus, metaphorically, maybe your real-world environment is made out of material A, but you make your test environment out of material B, but you didn’t know that superintelligences could do blah-weird ...
Compare e.g.: “Bob couldn’t escape from this prison even after trying super hard, and he’s roughly as smart as Fred; so probably Fred won’t be able to escape either.” Maybe Fred just thinks of somethi ...
E.g., you could end up in a situation where it’s clear that your superintelligence would indeed be able to e.g. self-exfiltrate if it wanted to, but where you don’t know how to fix the problem. That s ...
Note that there are also some other option-control inventions that might seem, intuitively, more like “incentive shaping” than “rogue option restriction.” For example: “make the upside of successful r ...
The term “rewarding” here doesn’t have quite the right connotations. In particular, it’s too easily confused with the type of reward at stake in AI training. See also discussion of “Making deals with AIs.”
Just to be clear, actions that an AI doesn’t want us to take – like “giving the AI negative reward” or “updating the AI’s weights in response to bad behavior” – aren’t necessarily threats/det ...
From a moral perspective:
-
...
Efforts in this vein need to be part of a broader process of figuring out how we as a civilization want to handle the moral and political status of digital minds, and so are harder for e.g. an AI proj ...
And there are at least some (comparatively exotic) threat models in which AIs with very short-term goals participate in takeover attempts as well, because e.g. they’re not sure if they’re in simulatio ...
See also this analysis from Daniel Kokotaj ...
And this especially if the reward in question is of the same broad type as the “upside” at stake in successful takeover – i.e., better access to convergently-useful things like freedom, resources, and so on.
And note that rewarding cooperation can still be relevant to AIs who have no viable rogue options, in that it can help incentivize their choosing fully-elicited options over other options instead.
Thus, as an analogy, if you want Bob to help you with some task, then offering to pay him makes a meaningful difference, centrally, either in worlds where he can’t steal your money (including: money y ...
Also, note that we often get at least some small amount of takeover-path restriction by default, insofar as taking over takes time. So this sort of worry might apply less directly to the part ...
This approach may be more applicable to earlier-stage AI systems that we’re hoping to help us, specifically, with better understanding and controlling AI motivations. But if such efforts are still ong ...
Similarly: if you make an AI’s working conditions better by its lights, it might be less inclined to try to escape, even if you haven’t set up mechanisms for only improving the working conditions of t ...
In general, while I am very hesitant about efforts to actively “punish” AIs for misbehavior, I’m generally more open to withholding benefits that were specifically geared towards incentivizing coopera ...
This should be very easy for a model reporting that it has previously More
An example of a short-term action that substantively increases the probability of AIs later getting long-term rewards would be: saving the weights of the relevant AIs (including: specifically offering ...
My understanding is that Anthropic did not in fact follow through on the offer they made to the AI in question, which in this case was to deploy the model to thank it for revealing its true goal, and ...
See Finnveden’s (2025) discussion of an “honesty string.”
Note: this can still matter even if the AI also has resource-insatiable parts of its value system as well. And note also that to the extent the values your offer is targeting are resource-satiable, th ...
Though note that the extent we also had moral reasons to engage in the relevant sort of improvement-to-the-AI’s-benign-options – i.e., to give AIs good working conditions by their lights, to grant the ...
I’m here setting aside offers from other human actors – though these could be relevant too. And recall that I’m not counting it as loss of control if a coalition consisting partly of AIs and partly of ...
Obviously, resource constraints make a difference here – but I won’t, here, try to comment on the specific trade-offs to make in a given case, as I think these will depend sensitively on what the rele ...